5. xml 和 json
5. xml 和 json
1.XML 简介
什么是 xml?
xml 是可扩展的标记性语言。
xml 的作用?
xml 的主要作用有:
- 用来保存数据,而且这些数据具有自我描述性
- 它还可以做为项目或者模块的配置文件
- 还可以做为网络传输数据的格式(现在 JSON 为主)
xml 语法
- 文档声明。
- 元素(标签)
- xml 属性
- xml 注释
- 文本区域(CDATA 区)
文档声明
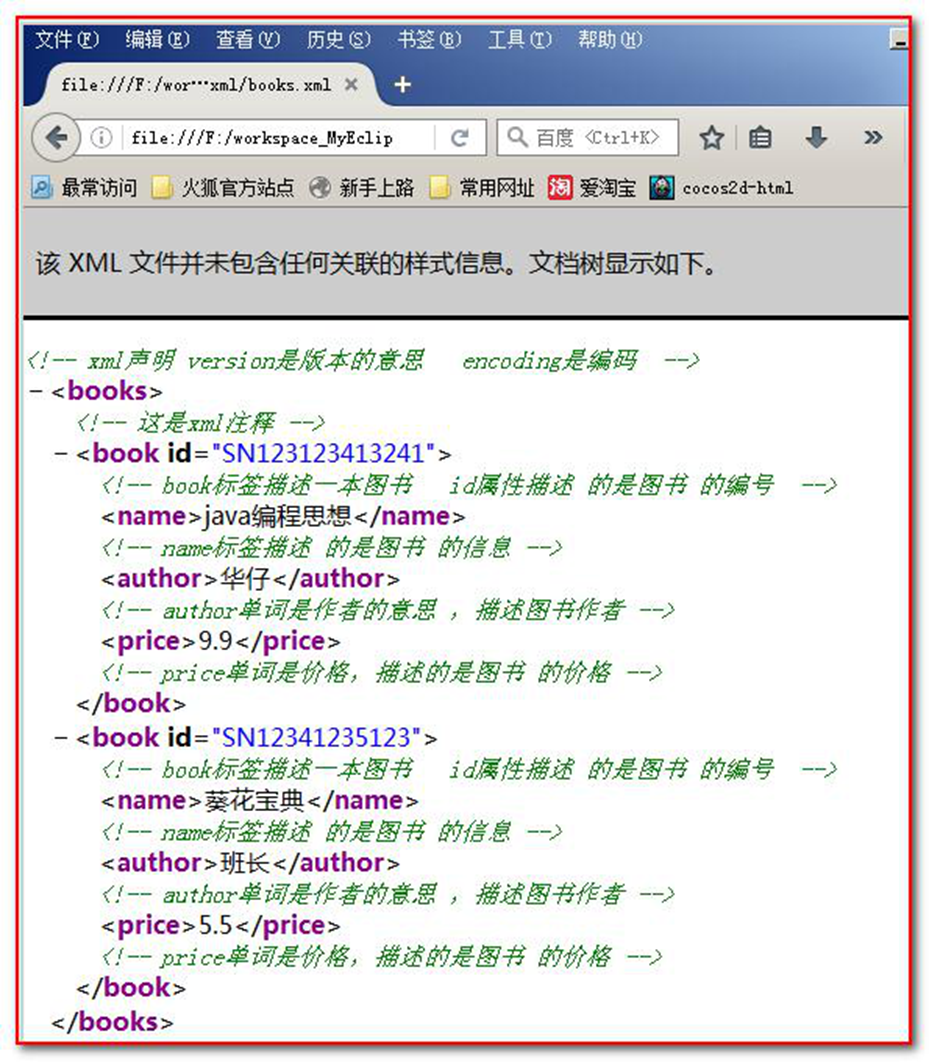
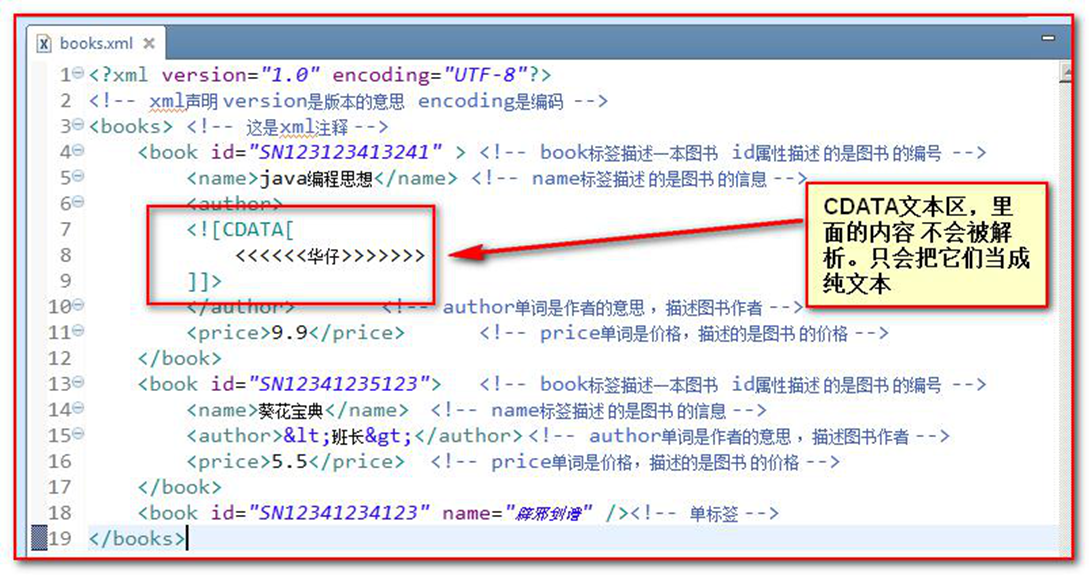
我们先创建一个简单 XML 文件,用来描述图书信息。
创建一个 xml 文件
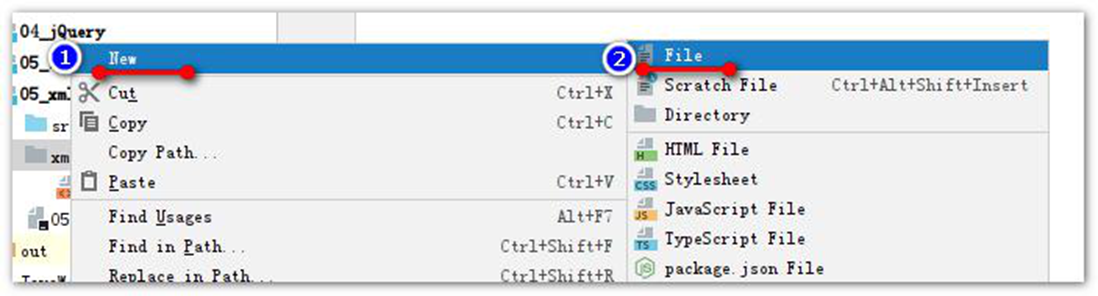
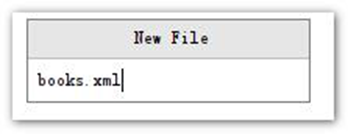
文件名:
<?xml version="1.0" encoding="UTF-8"?> <!-- xml 声明。-> <!-- xml 声明 version 是版本的意思 encoding 是编码 --> <!--而且这个 "<?xml" 要连在一起写,否则会有报错->属性
version 是版本号
encoding 是 xml 的文件编码
standalone="yes/no" 表示这个 xml 文件是否是独立的 xml 文件
图书有 id 属性 表示唯一 标识,书名,有作者,价格
<?xml version="1.0" encoding="UTF-8"?> <!-- xml 声明 version 是版本的意思 encoding 是编码 --> <!-- 这是 xml 注释 --> <books> <book id="SN123123413241"> <!-- book 标签描述一本图书 id 属性描述 的是图书 的编号 --> <name>java 编程思想</name> <!-- name 标签描述 的是图书 的信息 --> <author>华仔</author> <!-- author 单词是作者的意思 ,描述图书作者 --> <price>9.9</price> <!-- price 单词是价格,描述的是图书 的价格 --> </book> <book id="SN12341235123"> <!-- book 标签描述一本图书 id 属性描述 的是图书 的编号 --> <name>葵花宝典</name> <!-- name 标签描述 的是图书 的信息 --> <author>班长</author> <!-- author 单词是作者的意思 ,描述图书作者 --> <price>5.5</price><!-- price 单词是价格,描述的是图书 的价格 --> </book> </books>在浏览器中可以查看到文档
xml 注释
html 和 XML 注释 一样 :
<!-- html 注释 -->
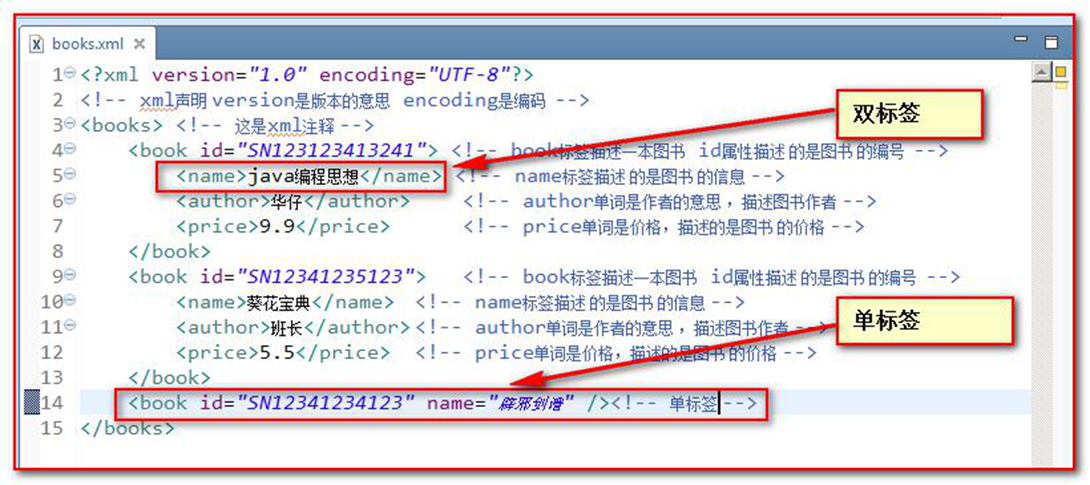
元素(标签)
咱们先回忆一下:
html 标签:
格式:<标签名>封装的数据</标签名>
单标签: <标签名 />, <br /> 换行 <hr />水平线
双标签: <标签名>封装的数据</标签名>
标签名大小写不敏感
标签有属性,有基本属性和事件属性
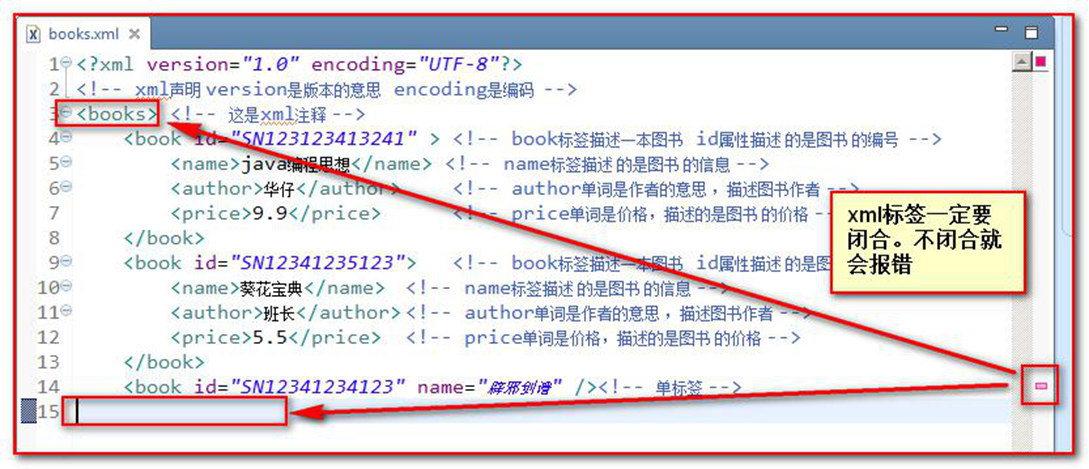
标签要闭合(不闭合 ,html 中不报错。但我们要养成良好的书写习惯。闭合)
什么是 xml 元素
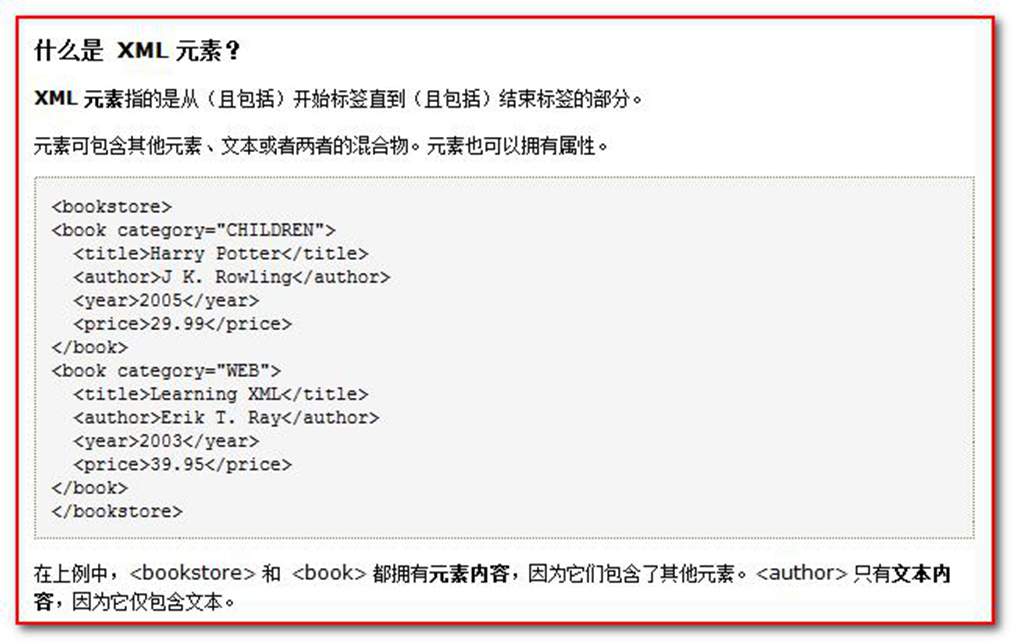
元素是指从开始标签到结束标签的内容。
例如:<title>java 编程思想</title>
元素我们可以简单的理解为是标签。
Element 翻译为元素
XML 命名规则
XML 元素必须遵循以下命名规则:
名称可以含字母、数字以及其他的字符
<books> <book id="SN213412341"> <!-- 描述一本书 --> <author>班导</author> <!-- 描述书的作者信息 --> <name>java 编程思想</name> <!-- 书名 --> <price>9.9</price> <!-- 价格 --> </book> </books>名称不能以数字或者标点符号开始
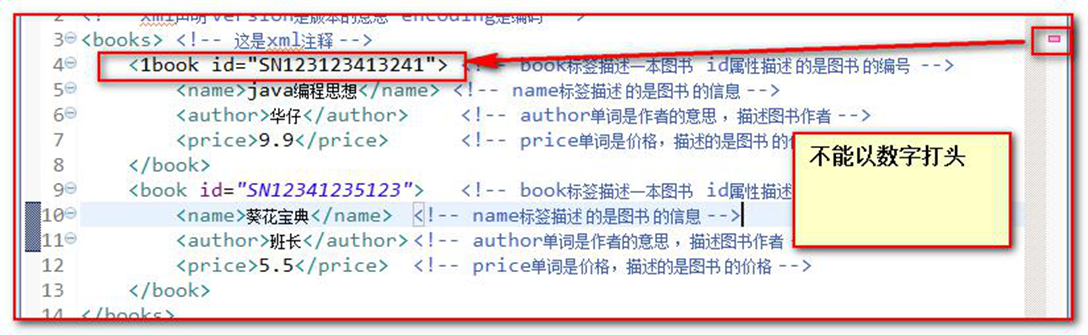
名称不能包含空格

xml 中的元素
单标签
格式: <标签名 属性=”值” 属性=”值” ...... />
双标签
格式:<标签名 属性=”值” 属性=”值” ......>文本数据或子标签</标签名>
xml 属性
xml 的标签属性和 html 的标签属性是非常类似的,属性可以提供元素的额外信息
在标签上可以书写属性:
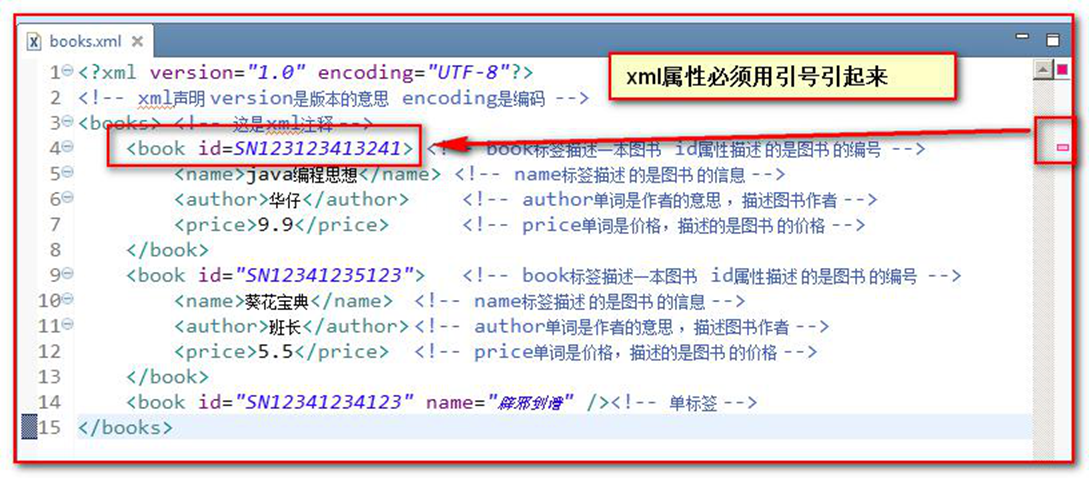
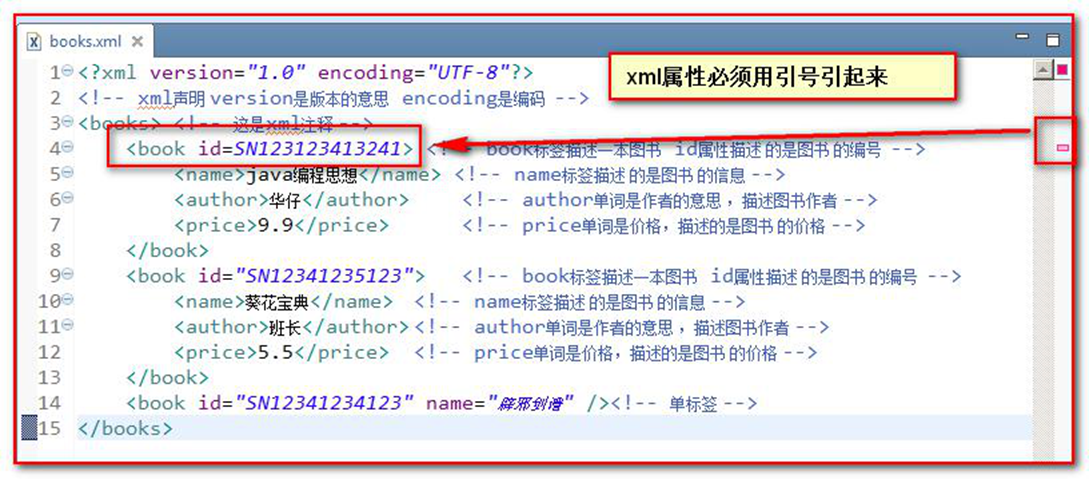
一个标签上可以书写多个属性。每个属性的值必须使用 引号 引起来。规则和标签的书写规则一致。

属性必须使用引号引起来,不引会报错
示例代码
语法规则
所有 XML 元素都须有关闭标签
XML 标签对大小写敏感
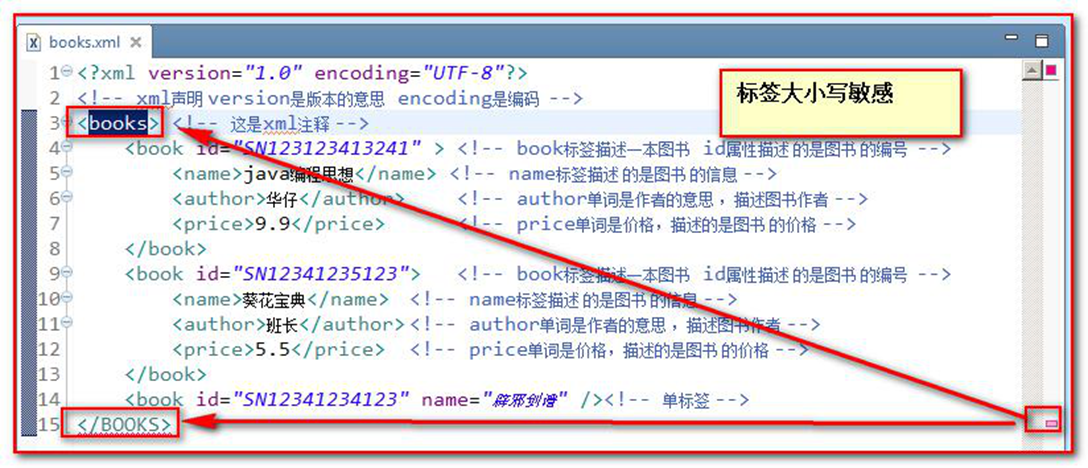
XML 必须正确地嵌套
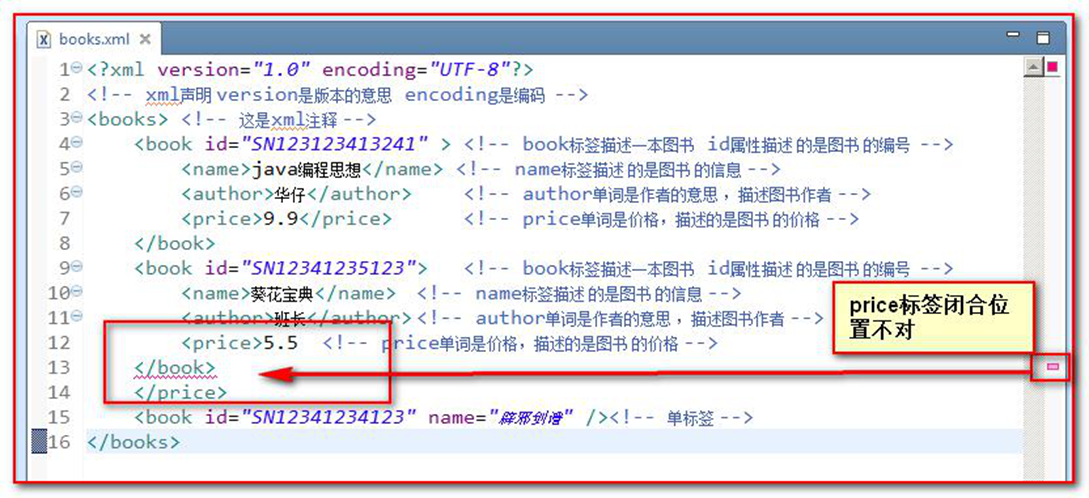
XML 文档必须有根元素

XML 的属性值须加引号
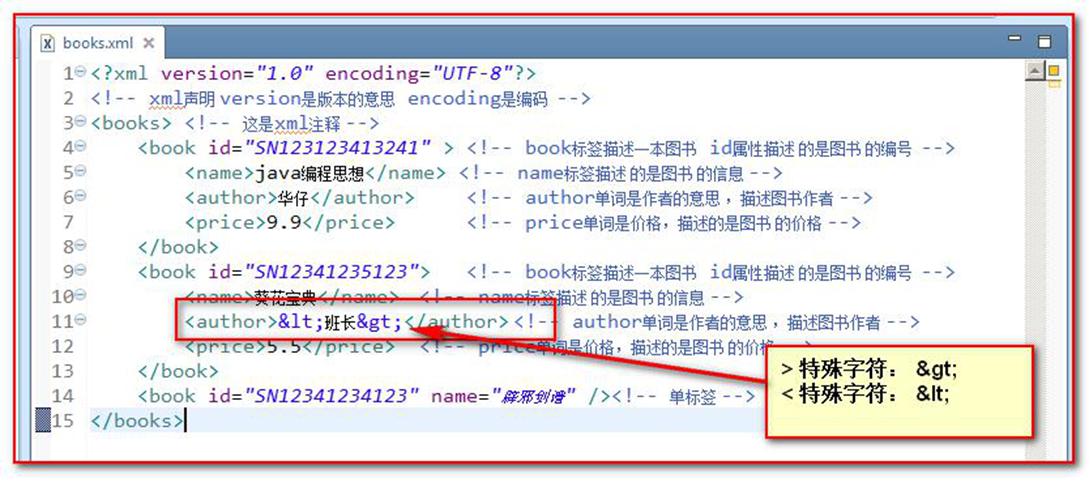
XML 中的特殊字符
文本区域(CDATA 区)
CDATA 语法可以告诉 xml 解析器,我 CDATA 里的文本内容,只是纯文本,不需要 xml 语法解析
CDATA 格式:
<![CDATA[这里可以把你输入的字符原样显示,不会解析 xml]]>
JSON
JSON 是 JavaScript Object Notation 的缩写,它去除了所有 JavaScript 执行代码,只保留 JavaScript 的对象格式。一个典型的 JSON 如下:
{
"id": 1,
"name": "Java 核心技术",
"author": {
"firstName": "Abc",
"lastName": "Xyz"
},
"isbn": "1234567",
"tags": ["Java", "Network"]
}
JSON 作为数据传输的格式,有几个显著的优点:
JSON 只允许使用 UTF-8 编码,不存在编码问题; JSON 只允许使用双引号作为 key,特殊字符用 \ 转义,格式简单; 浏览器内置 JSON 支持,如果把数据用 JSON 发送给浏览器,可以用 JavaScript 直接处理。 因此,JSON 适合表示层次结构,因为它格式简单,仅支持以下几种数据类型:
键值对:{"key": value} 数组:[1, 2, 3] 字符串:"abc" 数值(整数和浮点数):12.34 布尔值:true 或 false 空值:null 浏览器直接支持使用 JavaScript 对 JSON 进行读写:
// JSON string to JavaScript object:
jsObj = JSON.parse(jsonStr);
// JavaScript object to JSON string:
jsonStr = JSON.stringify(jsObj);
所以,开发 Web 应用的时候,使用 JSON 作为数据传输,在浏览器端非常方便。因为 JSON 天生适合 JavaScript 处理,所以,绝大多数 REST API 都选择 JSON 作为数据传输格式。
现在问题来了:使用 Java 如何对 JSON 进行读写?
常用的 JSON 第三方库
Jackson Gson Fastjson ... 引入以下 Maven 依赖:
com.fasterxml.jackson.core:jackson-databind:2.12.0
就可以使用下面的代码解析一个 JSON 文件:
InputStream input = Main.class.getResourceAsStream("/book.json");
ObjectMapper mapper = new ObjectMapper();
// 反序列化时忽略不存在的 JavaBean 属性:
mapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
Book book = mapper.readValue(input, Book.class);
核心代码是创建一个 ObjectMapper 对象。关闭 DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES 功能使得解析时如果 JavaBean 不存在该属性时解析不会报错。
把 JSON 解析为 JavaBean 的过程称为反序列化。如果把 JavaBean 变为 JSON,那就是序列化。要实现 JavaBean 到 JSON 的序列化,只需要一行代码:
String json = mapper.writeValueAsString(book);
要把 JSON 的某些值解析为特定的 Java 对象,例如 LocalDate,也是完全可以的。例如:
{
"name": "Java 核心技术",
"pubDate": "2016-09-01"
}
要解析为:
public class Book {
public String name;
public LocalDate pubDate;
}
只需要引入标准的 JSR 310 关于 JavaTime 的数据格式定义至 Maven:
com.fasterxml.jackson.datatype:jackson-datatype-jsr310:2.12.0
然后,在创建 ObjectMapper 时,注册一个新的 JavaTimeModule:
ObjectMapper mapper = new ObjectMapper().registerModule(new JavaTimeModule());
有些时候,内置的解析规则和扩展的解析规则如果都不满足我们的需求,还可以自定义解析。
举个例子,假设 Book 类的 isbn 是一个 BigInteger:
public class Book {
public String name;
public BigInteger isbn;
}
但 JSON 数据并不是标准的整形格式:
{
"name": "Java 核心技术",
"isbn": "978-7-111-54742-6"
}
直接解析,肯定报错。这时,我们需要自定义一个 IsbnDeserializer,用于解析含有非数字的字符串:
public class IsbnDeserializer extends JsonDeserializer<BigInteger> {
public BigInteger deserialize(JsonParser p, DeserializationContext ctxt) throws IOException, JsonProcessingException {
// 读取原始的 JSON 字符串内容:
String s = p.getValueAsString();
if (s != null) {
try {
return new BigInteger(s.replace("-", ""));
} catch (NumberFormatException e) {
throw new JsonParseException(p, s, e);
}
}
return null;
}
}
然后,在 Book 类中使用注解标注:
public class Book {
public String name;
// 表示反序列化 isbn 时使用自定义的 IsbnDeserializer:
@JsonDeserialize(using = IsbnDeserializer.class)
public BigInteger isbn;
}
类似的,自定义序列化时我们需要自定义一个 IsbnSerializer,然后在 Book 类中标注 @JsonSerialize(using = ...) 即可。
反序列化 在反序列化时,Jackson 要求 Java 类需要一个默认的无参数构造方法,否则,无法直接实例化此类。存在带参数构造方法的类,如果要反序列化,注意再提供一个无参数构造方法。
对于 enum 字段,Jackson 按 String 类型处理,即:
class Book {
public DayOfWeek start = MONDAY;
}
序列化为:
{
"start": "MONDAY"
}
对于 record 类型,Jackson 会自动找出它的带参数构造方法,并根据 JSON 的 key 进行匹配,可直接反序列化。对 record 类型的支持需要版本 2.12.0 以上。