7. 面向对象(上)
7. 面向对象(上)
面向过程和面向对象的区别:
面向过程:
主要关注点是:实现的具体过程,因果关系。
优点:对于业务逻辑比较简单的程序,可以达到快速开发,前期投入成本较低。
缺点:采用面向过程的方式开发很难解决非常复杂的业务逻辑,另外面向过程的方式最终导致的软件拓展力差。另外,由于没有独立体的概念,所以无法达到组件的复用。
面向对象:
主要关注点是:主要关注对象能完成那些功能。
优点:耦合度低,拓展力强。更容易解决现实世界当中更复杂的业务逻辑,组件复用性强。
缺点:前期投入成本高,需要进行独立体的抽取,大量的系统分析与统计。
面向对象方式:
采用面向对象的方式开发一个软件,生命周期当中:(整个生命周期中贯穿使用 oo 面向对象方式)。
- 面向对象的分析:
ooa - 面向对象的设计:
ood - 面向对象的编程:
oop
类和对象
Java 是面向对象的程序设计语言,类是面向对象的重要内容,我们可以把类当成一种自定义数据类型,可以使用类来定义变量,这种类型的变量统称为引用变量。也就是说,所有类是引用数据类型。
类和对象的概念:
类在现实世界当中是不存在的,是一个模板,是一个概念。是人类大脑思考抽象的结果。
类代表了一类事物:
在现实世界当中,对象 A 与对象 B 之间具有共同特征,进行抽象总结出一个模板,这个模板被称为类。
状态:一个类的属性。
动作:一个类的方法。
对象:对象是实际存在的个体,现实世界当中实际存在。
实例:对象还有一个名字叫做实例。
实例化:通过类这个模板创建对象的过程,叫做实例化。
抽象:多个对象具有共同特征,进行思考总结抽取共同特征的过程。
提示
类描述的是对象的共同特征。
共同特征例如:身高特征
这个身高特征在访问的时候,必须先创建对象,通过对象去访问这个特征。因为这个特征具体在某个对象上之后,值不同。有的对象身高 1.80,有的身高 1.9。
定义类
Java 语言里定义类的简单语法如下:
[修饰符] class 类名 {
零到多个构造器定义..
零到多个Field...
零到多个方法..
}
修饰符可以是 public、final、abstract,或者完全省略这三个修饰符,类名只要是一个合法的标识符即可。
提示
如果从程序的可读性方面来看,Java 类名必须是由一个或多个有意义的单词连缀而成的,每个单词首字母大写,其他字母全部小写,单词与单词之间不要使用任何分隔符。
对一个类定义而言,可以包含三种最常见的成员:构造器、Field 和方法,三种成员都可以定义零个或多个,如果三种成员都只定义零个,就是定义了一个空类,这没有太大的实际意义。
类里各成员之间的定义顺序没有任何影响,各成员之间可以相互调用,但需要指出的是,static 修饰的成员不能访问没有 static 修饰的成员。
Field 用于定义该类或该类的实例所包含的状态数据,方法则用于定义该类或该类的实例的行为特征或者功能实现。构造器用于构造该类的实例,Java 语言通过 new 关键字来调用构造器,从而返回该类的实例。
构造器是一个类创建对象的根本途径,如果一个类没有构造器,这个类通常无法创建实例。因此, Java 语言提供了一个功能:==如果程序员没有为一个类编写构造器,则系统会为该类提供一个默认的构造器。==一旦程序员为一个类提供了构造器,系统将不再为该类提供构造器。
定义 Field
定义 Field 的语法格式如下:
[修饰符] Field类型 Field名 [= 默认值];
Field 语法格式的详细说明如下。
修饰符:
修饰符可以省略,也可以是
public、protected、private、static、final,其中public、protected、private三个最多只能出现其中之一,可以与static、final组合起来修饰 Field。
Field 类型:
Field 类型可以是 Java 语言允许的任何数据类型,包括基本类型和现在介绍的引用类型。
Field 名:
Field 名只要是一个合法的标识符即可。
默认值:
定义 Field 还可以指定一个可选的默认值。
相关信息
如果从程序可读性角度来看,Field 名应该由一个或多个有意义的单词连缀而成,第一个单词首字母小写,后面每个单词首字母大写,其他字母全部小写,单词与单词之间不要使用任何分隔符。
Field 是一种比较难以翻译的名词。有些资料、书籍将 Field 翻译为属性、字段、域。
如果一定要给 Field 一个准确的中文称呼,可以将其称为“成员变量”——成员变量包括实例变量和类变量。
定义方法
定义方法的语法格式如下:
[修饰符] 方法返回值类型方法名 (形参列表){
//由零条到多条可执行性语句组成的方法体
}
方法语法格式的详细说明如下。
修饰符:
修饰符可以省略,也可以是
public、protected、private、static、final、abstract,其中public、protected、private三个最多只能出现其中之一;abstract和final最多只能出现其中之一,它们可以与static组合起来修饰方法。
方法返回值类型:
返回值类型可以是 Java 语言允许的任何数据类型,包括基本类型和引用类型;如果声明了方法返回值类型,则方法体内必须有一个有效的
return语句,该语句返回一个变量或一个表达式,这个变量或者表达式的类型必须与此处声明的类型匹配。除此之外,如果一个方法没有返回值,则必须使用void来声明没有返回值。
方法名:
方法名的命名规则与 Field 命名规则基本相同,但通常建议方法名以英文中的动词开头。
形参列表:
形参列表用于定义该方法可以接受的参数,形参列表由零组到多组“参数类型形参名”组合而成,多组参数之间以英文逗号
,隔开,形参类型和形参名之间以英文空格隔开。一旦在定义方法时指定了形参列表,则调用该方法时必须传入对应的参数值——谁调用方法,谁负责为形参赋值。
方法体里多条可执行性语句之间有严格的执行顺序,排在方法体前面的语句总是先执行,排在方法体后面的语句总是后执行。
static 关键字
static 是一个特殊的关键字,它可用于修饰方法、Field 等成员。
static 修饰的成员表明它属于这个类本身,而不属于该类的单个实例,因为通常把 static 修饰的 Field 和方法也称为类 Field、类方法。
不使用 static 修饰的普通方法、Field 则属于该类的单个实例,而不属于该类。
因为通常把不使用 static 修饰的 Field 和方法也称为实例 Field、实例方法。
由于 static 的英文直译就是静态的意思,因此有时也把 static 修饰的 Field 和方法称为静态 Field 和静态方法,把不使用 static 修饰的 Field 和方法称为非静态 Field 和非静态方法。
静态成员不能直接访问非静态成员。
相关信息
虽然绝大部分资料都喜欢把 static 称为静态,但实际上这种说法很模糊,完全无法说明 static 的真正作用。
static 的真正作用就是用于区分 Field、方法、内部类、初始化块这四种成员到底属于类本身还是属于实例。
在类中定义的成员,有 static 修饰的成员属于类本身,没有 static 修饰的成员属于该类的实例。
构造器
构造器是一个特殊的方法,定义构造器的语法格式与定义方法的语法格式很像,定义构造器的语法格式如下:
[修饰符] 构造器名 (形参列表){
//由零条到多条可执行性语句组成的构造器执行体
}
构造器语法格式的详细说明如下。
修饰符:
修饰符可以省略,也可以是 public、protected、private 其中之一。
构造器名:
构造器名必须和类名相同。
形参列表:
和定义方法形参列表的格式完全相同。
构造器既不能定义返回值类型,也不能使用 void 声明构造器没有返回值。
如果为构造器定义了返回值类型,或使用 void 声明构造器没有返回值,编译时不会出错,但 Java 会把这个所谓的构造器当成普通方法来处理。
相关信息
构造器不是没有返回值吗?为什么不能用 void 修饰呢?
简单地说,这是 Java 的语法规定。
实际上,类的构造器是有返回值的,当我们用 new 关键字来调用构造器时,构造器返回该类的实例,可以把这个类的实例当成构造器的返回值,因此构造器的返回值类型总是当前类,无须定义返回值类型。
但必须注意:不能在构造器里显式使用 return 来返回当前类的对象,因为构造器的返回值是隐式的。
定义一个 Person 类。
public class Person {
// 下面定义了两个Field
public String name;
public int age;
// 下面定义了一个say方法
public void say(String content) {
System.out.println(content);
}
}
上面的 Person 类代码里没有定义构造器,系统将为它提供一个默认的构造器,系统提供的构造器总是没有参数的。
对象的产生和使用
创建对象的根本途径是构造器,通过 new 关键字来调用某个类的构造器即可创建这个类的实例。
//定义p变量的同时并为p变量赋值
Person p = new Person();
如果访问权限允许,类里定义的方法和 Field 都可以通过类或实例来调用。
类或实例访问方法或 Field 的语法是:类.Field|方法,或者 实例.Field|方法,在这种方式中,类或实例是主调者,用于访问该类或该实例的指定 Field 或方法。
static 修饰的方法和 Field,既可通过类来调用,也可通过实例来调用;没有使用 static 修饰的普通方法和 Field,只可通过实例来调用。
// 调用p的name Field,直接为该Field赋值
p.name = "李刚";
// 调用p的say方法,声明say方法时定义了一个形参
// 调用该方法必须为形参指定一个值
p.say("Java语言很简单,学习很容易!");
// 直接输出p的name Field的值,将输出李刚
System.out.println(p.name);
上面代码中通过 Person 实例调用了 say 方法,调用方法时必须为方法的形参赋值。
因此在这行代码中调用 Person 对象的 say 方法时,必须为 say 方法传入一个字符串作为形参的参数值,这个字符串将被给 content 参数。
大部分时候,定义一个类就是为了重复创建该类的实例,同一个类的多个实例具有相同的特征,而类则是定义了多个实例的共同特征。
从某个角度来看,类定义的是多个实例的特征,因此类不是一种具体存在,实例才是具体存在。完全可以这样说:你不是人这个类,我也不是人这个类,我们都只是人的实例。
对象、引用
Person p = new Person();,这行代码创建了一个 Person 实例,也被称为 Person 对象,这个 Person 对象被赋给 p 变量。
在这行代码中实际产生了两个东西:一个是 p 变量,一个是 Person 对象。
从 Person 类定义来看,Person 对象应包含两个 Field,而 Field 是需要内存来存储的。因此,当创建 Person 对象时,必然需要有对应的内存来存储 Person 对象的 Field。
Person 对象由多块内存组成,不同内存块分别存储了 Person 对象的不同 Field。当把这个 Person 对象赋值给一个引用变量时,Java 会让引用变量指向这个对象。
也就是说,引用变量里存放的仅仅是一个引用,它指向实际的对象。
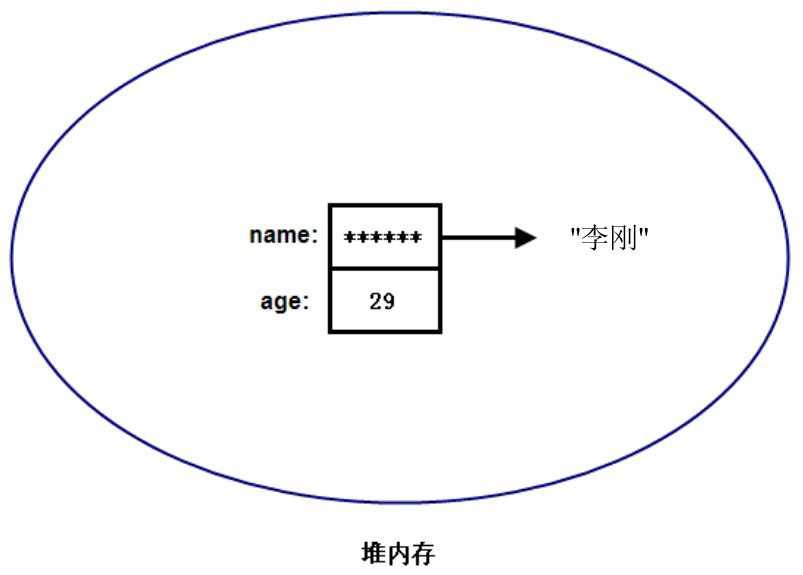
真正的 Person 对象则存放在堆(heap)内存中。
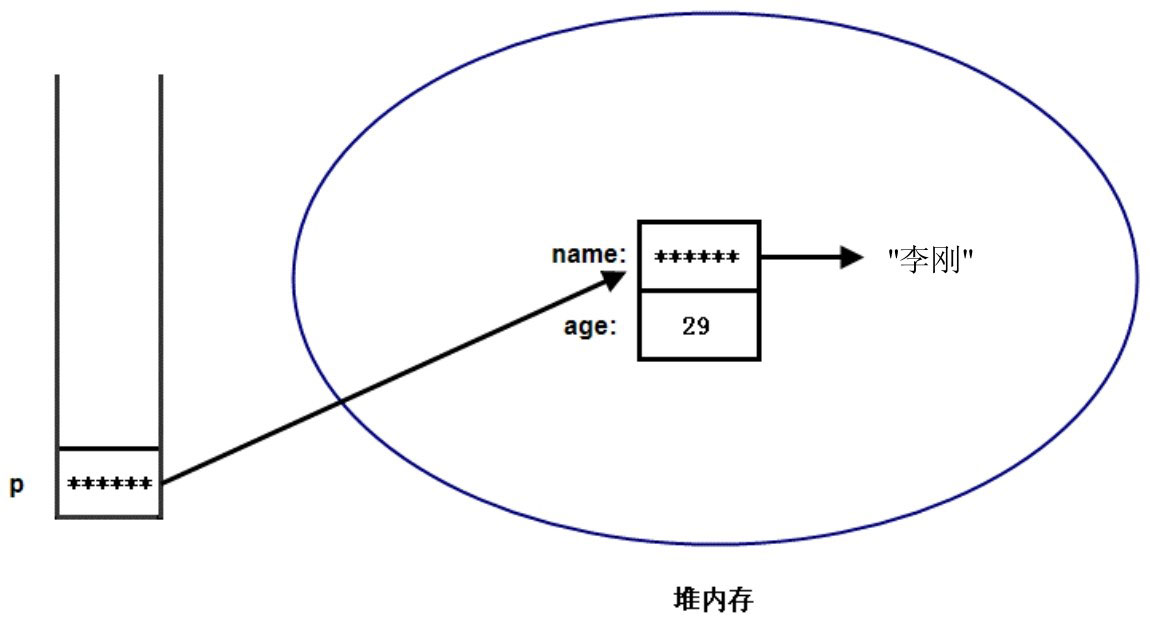
栈内存里的引用变量并未真正存储对象的 Field 数据,对象的 Field 数据实际存放在堆内存里;而引用变量只是指向该堆内存里的对象。
从这个角度来看,引用变量与 C 语言里的指针很像,它们都是存储一个地址值,通过这个地址来引用到实际对象。
当一个对象被创建成功以后,这个对象将保存在堆内存中,Java 程序不允许直接访问堆内存中的对象,只能通过该对象的引用操作该对象。
堆内存里的对象可以有多个引用,即多个引用变量指向同一个对象。
//将p变量的值赋值给p2变量
Person p2 = p;
上面代码把 p 变量的值赋值给 p2 变量,也就是将 p 变量保存的地址值赋给 p2 变量,这样 p2 变量和 p 变量将指向堆内存里的同一个 Person 对象。
不管访问 p2 变量的 Field 和方法,还是访问 p 变量的 Field 和方法,它们实际上是访问同一个 Person 对象的 Field 和方法,将会返回相同的访问结果。
如果堆内存里的对象没有任何变量指向该对象,那么程序将无法再访问该对象,这个对象也就变成了垃圾,Java 的垃圾回收机制将回收该对象,释放该对象所占的内存区。
因此,如果希望通知垃圾回收机制回收某个对象,只需切断该对象的所有引用变量和它之间的关系即可,也就是把这些引用变量赋值为 null。
对象的 this 引用
Java 提供了一个 this 关键字,this 关键字总是指向调用该方法的对象。
根据 this 出现位置的不同, this 作为对象的默认引用有两种情形:
- 构造器中引用该构造器正在初始化的对象;
- 在方法中引用调用该方法的对象。
this 关键字最大的作用就是让类中一个方法,访问该类里的另一个方法或 Field。
假设定义了一个 Dog 类,这个 Dog 对象的 run 方法需要调用它的 jump 方法,那么应该如何做?
public class Dog {
// 定义一个jump方法
public void jump() {
System.out.println("正在执行jump方法");
}
// 定义一个run方法,run方法需要借助jump方法
public void run() {
Dog d = new Dog();
d.jump();
System.out.println("正在执行run方法");
}
}
使用这种方式来定义这个 Dog 类,确实可以实现在 run 方法中调用 jump 方法。再提供一个程序来创建 Dog 对象,并调用该对象的 run 方法。
public class DogTest {
public static void main(String[] args) {
// 创建Dog对象
Dog dog = new Dog();
// 调用Dog对象的run方法
dog.run();
}
}
在上面的程序中,一共产生了两个 Dog 对象,在 Dog 类的 run 方法中,程序创建了一个 Dog 对象,并使用名为 d 的引用变量来指向该 Dog 对象;在 DogTest 的 main 方法中,程序再次创建了一个 Dog 对象,并使用名为 dog 的引用变量来指向该 Dog 对象。
这里产生了两个问题。
第一个问题:在 run 方法中调用 jump 方法时是否一定需要一个 Dog 对象?
第二个问题:是否一定需要重新创建一个 Dog 对象?
第一个问题的答案是肯定的,因为没有使用 static 修饰的 Field 和方法都必须使用对象来调用。
第二个问题的答案是否定的,因为当程序调用 run 方法时,一定会提供一个 Dog 对象,这样就可以直接使用这个已经存在的 Dog 对象,而无须重新创建新的 Dog 对象了。
为此,我们需要在 run 方法中获得调用该方法的对象,通过 this 关键字就可以满足这个要求。
this 可以代表任何对象,当 this 出现在某个方法体中时,它所代表的对象是不确定的,但它的类型是确定的,它所代表的对象只能是当前类;只有当这个方法被调用时,它所代表的对象才被确定下来:谁在调用这个方法,this 就代表谁。
public class Dog {
// 定义一个jump方法
public void jump() {
System.out.println("正在执行jump方法");
}
// 定义一个run方法,run方法需要借助jump方法
public void run() {
// 使用this引用调用run()方法的对象
this.jump();
System.out.println("正在执行run方法");
}
}
在现实世界里,对象的一个方法依赖于另一个方法的情形如此常见,例如,吃饭方法依赖于拿筷子方法,写程序方法依赖于敲键盘方法,这种依赖都是同一个对象两个方法之间的依赖。
因此,Java 允许对象的一个成员直接调用另一个成员,可以省略 this 前缀。也就是说,将上面的 run 方法改为如下形式也完全正确。
public void run() {
jump();
System.out.println("正在执行run方法");
}
对于 static 修饰的方法而言,则可以使用类来直接调用该方法,如果在 static 修饰的方法中使用 this 关键字,则这个关键字就无法指向合适的对象。
所以,static 修饰的方法中不能使用 this 引用。由于 static 修饰的方法不能使用 this 引用,所以 static 修饰的方法不能访问不使用 static 修饰的普通成员,因此 Java 语法规定:静态成员不能直接访问非静态成员。
相关信息
省略 this 前缀只是一种假象,虽然程序员省略了调用jump()方法之前的 this,但实际上这个 this 依然是存在的。
根据汉语语法习惯:完整的语句至少包括主语、谓语、宾语,在面向对象的世界里,主、谓、宾的结构完全成立,例如“猪八戒吃西瓜”是一条汉语语句,转换为面向对象的语法,就可以写成“猪八戒.吃(西瓜);”;
如果把调用属性、方法的对象称为“主调(主语调用者的简称)”;对于 Java 语言来说,调用属性、方法时,主调是必不可少的,即使代码中省略了主调,但实际的主调依然存在。
一般来说,如果调用 static 修饰的成员(包括方法、Field)时省略了前面的主调,那么默认使用该类作为主调;如果调用没有 static 修饰的成员(包括方法、Field)时省略了前面的主调,那么默认使用 this 作为主调。
下面程序演示了静态方法直接访问非静态方法时引发的错误。
public class StaticAccessNonStatic {
public void info() {
System.out.println("简单的info方法");
}
public static void main(String[] args) {
// 因为main方法是静态方法,而info是非静态方法
// 调用main方法的是该类本身,而不是该类的实例
// 因此省略的this无法指向有效的对象
info();
}
}
编译上面的程序,系统提示在info();代码行出现如下错误:
无法从静态上下文中引用非静态方法info()
static 修饰的方法属于类,而不属于对象,因此调用 static 修饰的方法的主调总是类本身;如果允许在 static 修饰的方法中出现 this 引用,那将导致 this 无法引用有效的对象,因此上面程序出现编译错误。
如果确实需要在静态方法中访问另一个普通方法,则只能重新创建一个对象。
//重新创建一个对象来调用info方法
new StaticAccessNonStatic().info();
大部分时候,普通方法访问其他方法、Field 时无须使用 this 前缀,但如果方法里有个局部变量和 Field 同名,但程序又需要在该方法里访问这个被覆盖的 Field,则必须使用 this 前缀。
除此之外,this 引用也可以用于构造器中作为默认引用,由于构造器是直接使用 new 关键字来调用,而不是使用对象来调用的,所以 this 在构造器中引用的是该构造器进行初始化的对象。
public class ThisInConstructor {
// 定义一个名为foo的Field
public int foo;
public ThisInConstructor() {
// 在构造器里定义一个foo变量
int foo = 0;
// 使用this代表此构造器进行初始化的对象
// 下面的代码将会把刚创建对象的foo Field设置为6
this.foo = 6;
}
public static void main(String[] args) {
// 所有使用ThisInConstructor创建的对象的foo Field
// 都将被设为6,所以下面代码将输出6
System.out.println(new ThisInConstructor().foo);
}
}
与普通方法类似的是,大部分时候,在构造器中访问其他 Field 和方法时都可以省略 this 前缀,但如果构造器中有一个与 Field 同名的局部变量,又必须在构造器中访问这个被覆盖的 Field,则必须使用 this 前缀。
当 this 作为对象的默认引用使用时,程序可以像访问普通引用变量一样来访问这个 this 引用,甚至可以把 this 当成普通方法的返回值。
public class ReturnThis {
public int age;
public ReturnThis grow() {
age++;
// return this,返回调用该方法的对象
return this;
}
public static void main(String[] args) {
ReturnThis rt = new ReturnThis();
// 可以连续调用同一个方法
rt.grow().grow().grow();
System.out.println("rt的age Field值是:" + rt.age);
}
}
从上面程序中可以看出,如果在某个方法中把 this 作为返回值,则可以多次连续调用同一个方法,从而使得代码更加简洁。
但是,这种把 this 作为返回值的方法可能造成实际意义的模糊,例如上面的 grow 方法,用于表示对象的生长,即 age Field 的值加 1,实际上不应该有返回值。
提示
使用 this 作为方法的返回值可以让代码更加简洁,但可能造成实际意义的模糊。
方法详解
方法是类或对象的行为特征的抽象,方法是类或对象最重要的组成部分。但从功能上来看,方法完全类似于传统结构化程序设计里的函数。值得指出的是,Java 里的方法不能独立存在,所有的方法都必须定义在类里。方法在逻辑上要么属于类,要么属于对象。
方法就是一段代码片段,并且这段代码片段可以完成某个特定的功能,可以被重复使用。方法定义在类体当中,一个类当中可以定义多个方法,方法编写的位置没有先后顺序,可以随意。
方法体中不能再定义方法!
方法体当中的代码遵守自上而下的顺序依次执行。
永远不要把方法当成独立存在的实体,正如现实世界由类和对象组成,而方法只能作为类和对象的附属,Java 语言里的方法也是一样。
Java 语言里方法的所属性主要体现在如下几个方面。
- 方法不能独立定义,方法只能在类体里定义。
- 从逻辑意义上来看,方法要么属于该类本身,要么属于该类的一个对象。
- 永远不能独立执行方法,执行方法必须使用类或对象作为调用者。
方法的参数传递机制
如果声明方法时包含了形参声明,则调用方法时必须给这些形参指定参数值,调用方法时实际传给形参的参数值也被称为实参。
Java 里方法的参数传递方式只有一种:值传递。所谓值传递,就是将实际参数值的副本(复制品)传入方法内,而参数本身不会受到任何影响。
提示
Java 里的参数传递类似于《西游记》里的孙悟空,孙悟空复制了一个假孙悟空,这个假孙悟空具有和孙悟空相同的能力,可除妖或被砍头。
但不管这个假孙悟空遇到什么事,真孙悟空不会受到任何影响。与此类似,传入方法的是实际参数值的复制品,不管方法中对这个复制品如何操作,实际参数值本身不会受到任何影响。
public class PrimitiveTransferTest {
public static void swap(int a, int b) {
// 下面三行代码实现a、b变量的值交换
// 定义一个临时变量来保存a变量的值
int tmp = a;
// 把b的值赋给a
a = b;
// 把临时变量tmp的值赋给a
b = tmp;
System.out.println("swap方法里,a的值是" + a + ";b的值是" + b);
}
public static void main(String[] args) {
int a = 6;
int b = 9;
swap(a, b);
System.out.println("交换结束后,变量a的值是" + a + ";变量b的值是" + b);
}
// swap方法里,a的值是9;b的值是6
// 交换结束后,变量a的值是6;变量b的值是9
}
从这个运行结果可以看出,main 方法里的变量 a 和 b,并不是 swap 方法里的 a 和 b。正如前面讲的,swap 方法的 a 和 b 只是 main 方法里变量 a 和 b 的复制品。
Java 程序总是从 main 方法开始执行,main 方法开始定义了 a、b 两个局部变量。
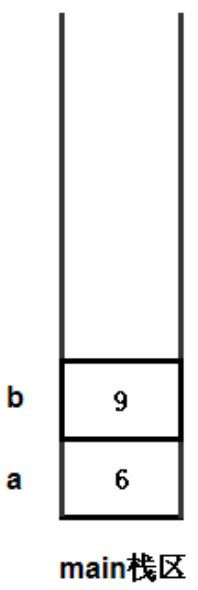
当程序执行 swap 方法时,系统进入 swap 方法,并将 main 方法中的 a、b 变量作为参数值传入 swap 方法,传入 swap 方法的只是 a、b 的副本,而不是 a、b 本身,进入 swap 方法后系统中产生了 4 个变量。
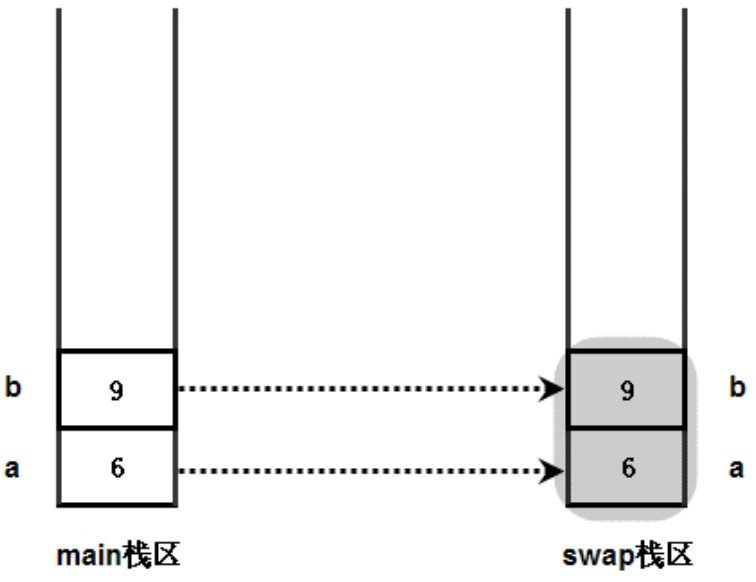
在 main 方法中调用 swap 方法时,main 方法还未结束。因此,系统分别为 main 方法和 swap 方法分配两块栈区,用于保存 main 方法和 swap 方法的局部变量。
main 方法中的 a、b 变量作为参数值传入 swap 方法,实际上是在 swap 方法栈区中重新产生了两个变量 a、b,并将 main 方法栈区中 a、b 变量的值分别赋给 swap 方法栈区中的 a、b 参数(就是对 swap 方法的 a、b 形参进行了初始化)。
此时,系统存在两个 a 变量、两个 b 变量,只是存在于不同的方法栈区中而已。
程序在 swap 方法中交换 a、b 两个变量的值,实际上是对图中灰色覆盖区域的 a、b 变量进行交换,交换结束后 swap 方法中输出 a、b 变量的值,看到 a 的值为 9,b 的值为 6。
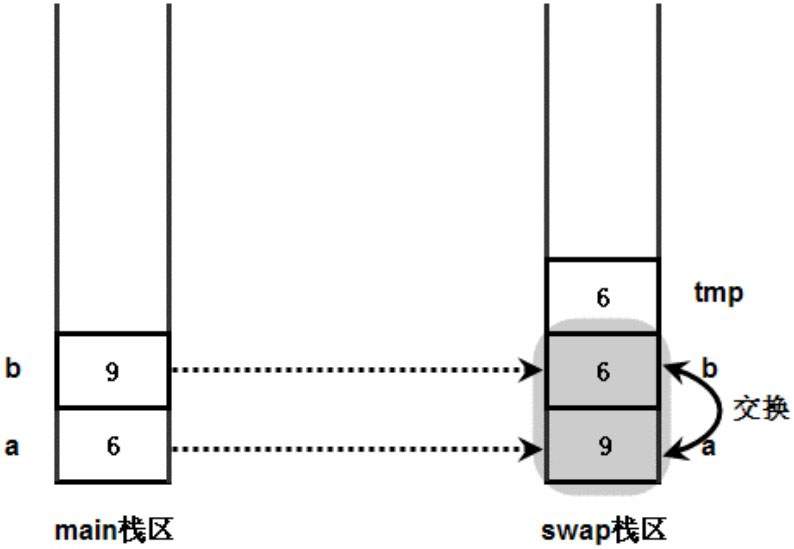
两个示意图中 main 方法栈区中 a、b 的值并未有任何改变,程序改变的只是 swap 方法栈区中的 a、b。这就是值传递的实质:当系统开始执行方法时,系统为形参执行初始化,就是把实参变量的值赋给方法的形参变量,方法里操作的并不是实际的实参变量。
前面看到的是基本类型的参数传递,Java 对于引用类型的参数传递,一样采用的是值传递方式。
class DataWrap {
public int a;
public int b;
}
public class ReferenceTransferTest {
public static void swap(DataWrap dw) {
// 下面三行代码实现dw的a、b两个Field值交换
// 定义一个临时变量来保存dw对象的a Field的值
int tmp = dw.a;
// 把dw对象的b Field的值赋给a Field
dw.a = dw.b;
// 把临时变量tmp的值赋给dw对象的b Field
dw.b = tmp;
System.out.println("swap方法里,a Field的值是" + dw.a + "; b Field的值是" + dw.b);
}
public static void main(String[] args) {
DataWrap dw = new DataWrap();
dw.a = 6;
dw.b = 9;
swap(dw);
System.out.println("交换结束后,a Field的值是" + dw.a + "; b Field的值是" + dw.b);
}
// swap方法里,a Field的值是9;b Field的值是6
// 交换结束后,a Field的值是9;b Field的值是6
}
从上面运行结果来看,在 swap 方法里,a、b 两个 Field 值被交换成功。不仅如此,main 方法里 swap 方法执行结束后,a、b 两个 Field 值也被交换了。
这很容易造成一种错觉:调用 swap 方法时,传入 swap 方法的就是 dw 对象本身,而不是它的复制品,但这只是一种错觉。
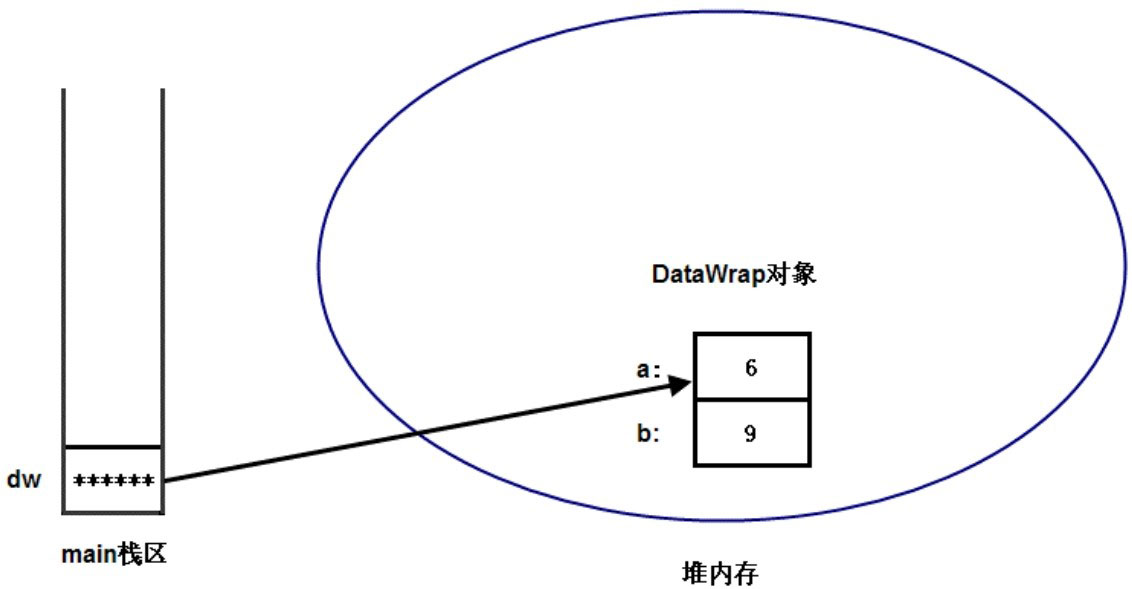
程序从 main 方法开始执行,main 方法开始创建了一个 DataWrap 对象,并定义了一个 dw 引用变量来指向 DataWrap 对象,这是一个与基本类型不同的地方。
创建一个对象时,系统内存中有两个东西:堆内存中保存了对象本身,栈内存中保存了引用该对象的引用变量。接着程序通过引用来操作 DataWrap 对象,把该对象的 a、b 两个 Field 分别赋值为 6、9。
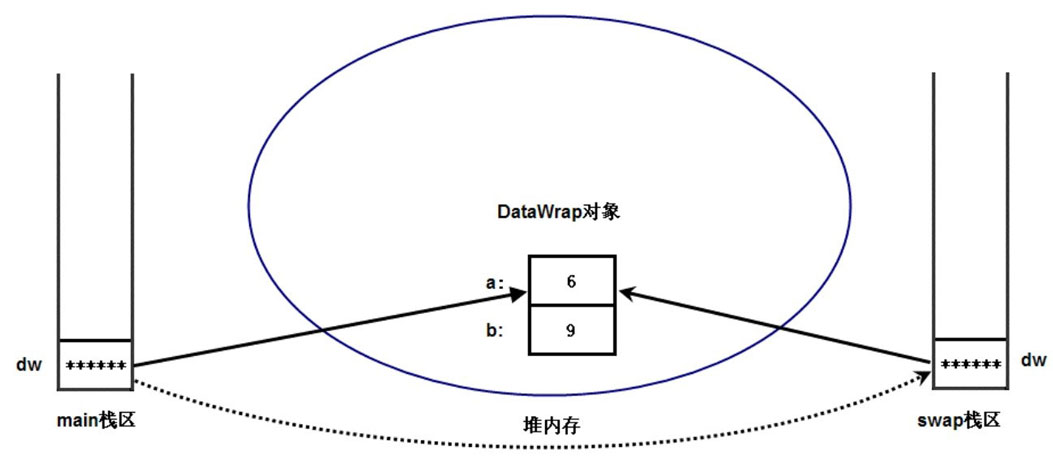
接下来,main 方法中开始调用 swap 方法,main 方法并未结束,系统会分别开辟出 main 和 swap 两个栈区,用于存放 main 和 swap 方法的局部变量。
调用 swap 方法时,dw 变量作为实参传入 swap 方法,同样采用值传递方式:把 main 方法里 dw 变量的值赋给 swap 方法里的 dw 形参,从而完成 swap 方法的 dw 形参的初始化。
main 方法中的 dw 是一个引用,它保存了 DataWrap 对象的地址值,当把 dw 的值赋给 swap 方法的 dw 形参后,即让 swap 方法的 dw 形参也保存这个地址值,即也会引用到堆内存中的 DataWrap 对象。
这种参数传递方式是不折不扣的值传递方式,系统一样复制了 dw 的副本传入 swap 方法,但关键在于 dw 只是一个引用变量,所以系统复制了 dw 变量,但并未复制 DataWrap 对象。
当程序在 swap 方法中操作 dw 形参时,由于 dw 只是一个引用变量,故实际操作的还是堆内存中的 DataWrap 对象。
此时,不管是操作 main 方法里的 dw 变量,还是操作 swap 方法里的 dw 参数,其实都是操作它所引用的 DataWrap 对象,它们操作的是同一个对象。
因此,当 swap 方法中交换 dw 参数所引用 DataWrap 对象的 a、b 两个 Field 值后,我们看到 main 方法中 dw 变量所引用 DataWrap 对象的 a、b 两个 Field 值也被交换了。
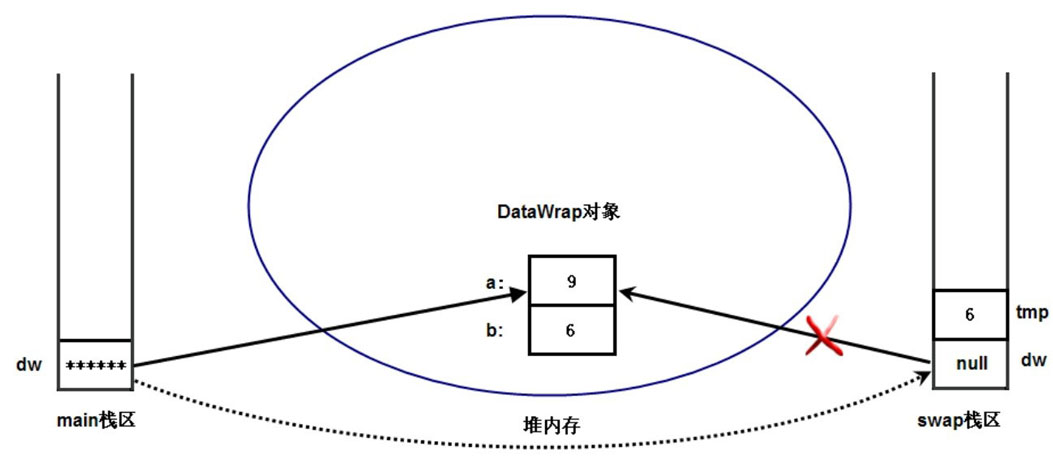
为了更好地证明 main 方法中的 dw 和 swap 方法中的 dw 是两个变量,在 swap 方法的最后一行增加如下代码:
//把dw直接赋值为null,让它不再指向任何有效地址
dw = null;
执行上面代码的结果是 swap 方法中的 dw 变量不再指向任何有效内存,程序其他地方不做任何修改。
main 方法调用了 swap 方法后,再次访问 dw 变量的 a、b 两个 Field,依然可以输出 9、6。可见 main 方法中的 dw 变量没有受到任何影响。
形参个数可变的方法
从 JDK 1.5 之后,Java 允许定义形参个数可变的参数,从而允许为方法指定数量不确定的形参。
如果在定义方法时,在最后一个形参的类型后增加三点(...),则表明该形参可以接受多个参数值,多个参数值被当成数组传入。
public class Varargs {
// 定义了形参个数可变的方法
public static void test(int a, String... books) {
// books被当成数组处理
for (String tmp : books) {
System.out.println(tmp);
}
// 输出整数变量a的值
System.out.println(a);
}
public static void main(String[] args) {
// 调用test方法
test(5, "疯狂Java讲义", "轻量级Java EE企业应用实战");
}
}
从 test 的方法体代码来看,形参个数可变的参数其实就是一个数组参数,也就是说,下面两个方法签名的效果完全一样。
//以可变个数形参来定义方法
public static void test(int a , String... books);
//下面采用数组形参来定义方法
public static void test(int a , String[] books);
这两种形式都包含了一个名为 books 的形参,在两个方法的方法体内都可以把 books 当成数组处理。但区别是调用两个方法时存在差别,对于以可变形参的形式定义的方法,调用方法时更加简洁,如下面代码所示。
test(5, "疯狂Java讲义","轻量级Java EE企业应用实战");
//调用test方法时传入一个数组
test(23, new String[]{"疯狂Java讲义","轻量级Java EE企业应用实战"});
对比两种调用 test 方法的代码,明显第一种形式更加简洁。实际上,即使是采用形参个数可变的形式来定义方法,调用该方法时也一样可以为个数可变的形参传入一个数组。
数组形式的形参可以处于形参列表的任意位置,但个数可变的形参只能处于形参列表的最后。也就是说,一个方法中最多只能有一个长度可变的形参。
提示
长度可变的形参只能处于形参列表的最后。
一个方法中最多只能包含一个长度可变的形参。
调用包含一个长度可变形参的方法时,这个长度可变的形参既可以传入多个参数,也可以传入一个数组。
递归方法
一个方法体内调用它自身,被称为方法递归。方法递归包含了一种隐式的循环,它会重复执行某段代码,但这种重复执行无须循环控制。
例如有如下数学题:
已知有一个数列:
f(0)=1,f(1)=4,f(n+2)=2 * f(n+1) + f(n),其中 n 是大于 0 的整数,求f(10)的值。
这个题可以使用递归来求得。
public class Recursive {
public static int fn(int n) {
if (n == 0) {
return 1;
} else if (n == 1) {
return 4;
} else {
// 方法中调用它自身,就是方法递归
return 2 * fn(n - 1) + fn(n - 2);
}
}
public static void main(String[] args) {
// 输出fn(10)的结果
System.out.println(fn(10));
}
}
在上面的 fn 方法体中,再次调用了 fn 方法,这就是方法递归。
注意 fn 方法里调用 fn 的形式:
return 2 * fn(n - 1) + fn(n - 2);
对于 fn(10),即等于 2 * fn(9) + fn(8),其中 fn(9) 又等于 2 * fn(8) + fn(7)……依此类推,最终会计算到 fn(2) 等于 2 * fn(1)+fn(0),即 fn(2) 是可计算的,然后一路反算回去,就可以最终得到 fn(10) 的值。
当一个方法不断地调用它本身时,必须在某个时刻方法的返回值是确定的,即不再调用它本身,否则这种递归就变成了无穷递归,类似于死循环。
因此定义递归方法时有一条最重要的规定:递归一定要向已知方向递归。
例如,如果把上面数学题改为如此:
已知有一个数列:
f(20)=1,f(21)=4,f(n+2)=2 * f(n+1) + f(n),其中n是大于 0 的整数,求f(10)的值。
那么 fn 的方法体就应该改为如下:
public static int fn(int n) {
if (n == 20) {
return 1;
} else if (n == 21) {
return 4;
} else {
// 方法中调用它自身,就是方法递归
return fn(n + 2) - 2 * fn(n + 1);
}
}
从上面的 fn 方法来看,当我们要计算 fn(10) 的值时,fn(10) 等于 fn(12) - 2 × fn(11),而 fn(11) 等于 fn(13)-2×fn(12) ……依此类推,直到 fn(19) 等于 fn(21)-2×fn(20),此时就可以得到 fn(19) 的值了,然后依次反算到 fn(10) 的值。
这就是递归的重要规则:对于求 fn(10) 而言,如果 fn(0) 和 fn(1) 是已知的,则应该采用 fn(n)=2 × fn(n-1) + fn(n-2) 的形式递归,因为小的一端已知;如果 fn(20) 和 fn(21) 是已知的,则应该采用fn(n) = fn(n+2) - 2 × fn(n+1)的形式递归,因为大的一端已知。
递归是非常有用的。例如,我们希望遍历某个路径下的所有文件,但这个路径下文件夹的深度是未知的,那么就可以使用递归来实现这个需求。系统可定义一个方法,该方法接受一个文件路径作为参数,该方法可遍历当前路径下的所有文件和文件路径——该方法中再次调用该方法本身来处理该路径下的所有文件路径。
提示
只要一个方法的方法体实现中再次调用(直接调用或者间接调用)了方法本身,就是递归方法。递归一定要向已知方向递归。
方法重载
Java 允许同一个类里定义多个同名方法,只要形参列表不同就行。如果同一个类中包含了两个或两个以上方法的方法名相同,但形参列表不同,则被称为方法重载。
在 Java 程序中确定一个方法需要三个要素:
- 调用者,也就是方法的所属者,既可以是类,也可以是对象;
- 方法名,方法的标识;
- 形参列表,当调用方法时,系统将会根据传入的实参列表匹配。
方法重载的要求就是两同一不同:同一个类中方法名相同,参数列表不同。
至于方法的其他部分,如方法返回值类型、修饰符等,与方法重载没有任何关系。
public class Overload {
// 下面定义了两个test方法,但方法的形参列表不同
// 系统可以区分这两个方法,这被称为方法重载
public void test() {
System.out.println("无参数");
}
public void test(String msg) {
System.out.println("重载的test方法" + msg);
}
public static void main(String[] args) {
Overload ol = new Overload();
// 调用test时没有传入参数,因此系统调用上面没有参数的test方法
ol.test();
// 调用test时传入了一个字符串参数
// 因此系统调用上面有一个字符串参数的test方法
ol.test("hello");
}
}
相关信息
为什么方法的返回值类型不能用于区分重载的方法?
对于 int f(){} 和 void f(){} 两个方法,如果这样调用 int result = f();,系统可以识别是调用返回值类型为 int 的方法;但 Java 调用方法时可以忽略方法返回值,如果采用如下方法来调用 f();,你能判断是调用哪个方法吗?如果你尚且不能判断,那么 Java 系统也会糊涂。
在编程过程中有一条重要规则:不要让系统糊涂,系统一糊涂,肯定就是你错了。
因此,Java 里不能使用方法返回值类型作为区分方法重载的依据。
不仅如此,如果被重载的方法里包含了长度可变的形参,则需要注意。
public class OverloadVarargs {
public void test(String msg) {
System.out.println("只有一个字符串参数的test方法");
}
// 因为前面已经有了一个test方法,test方法里有一个字符串参数
// 此处的长度可变形参里不包含一个字符串参数的形式
public void test(String... books) {
System.out.println("****形参长度可变的test方法****");
}
public static void main(String[] args) {
OverloadVarargs olv = new OverloadVarargs();
// 下面两次调用将执行第二个test方法
olv.test();
olv.test("aa", "bb");
// 下面调用将执行第一个test方法
olv.test("aa");
// 下面调用将执行第二个test方法
olv.test(new String[] {"aa"});
}
}
如果同一个类中定义了 test(String... books) 方法,同时还定义了一个 test(String) 方法,如果此时想要调用 test(String... books) 方法则 test(String... books) 方法的 books 不可能通过只传入一个字符串参数实现,如果只传入一个参数,系统会执行重载的 test(String) 方法。
如果需要调用 test(String... books) 方法,又只想传入一个字符串参数,则可采用传入字符串数组的形式:
olv.test(new String[]{"aa"});
JVM 内存模型
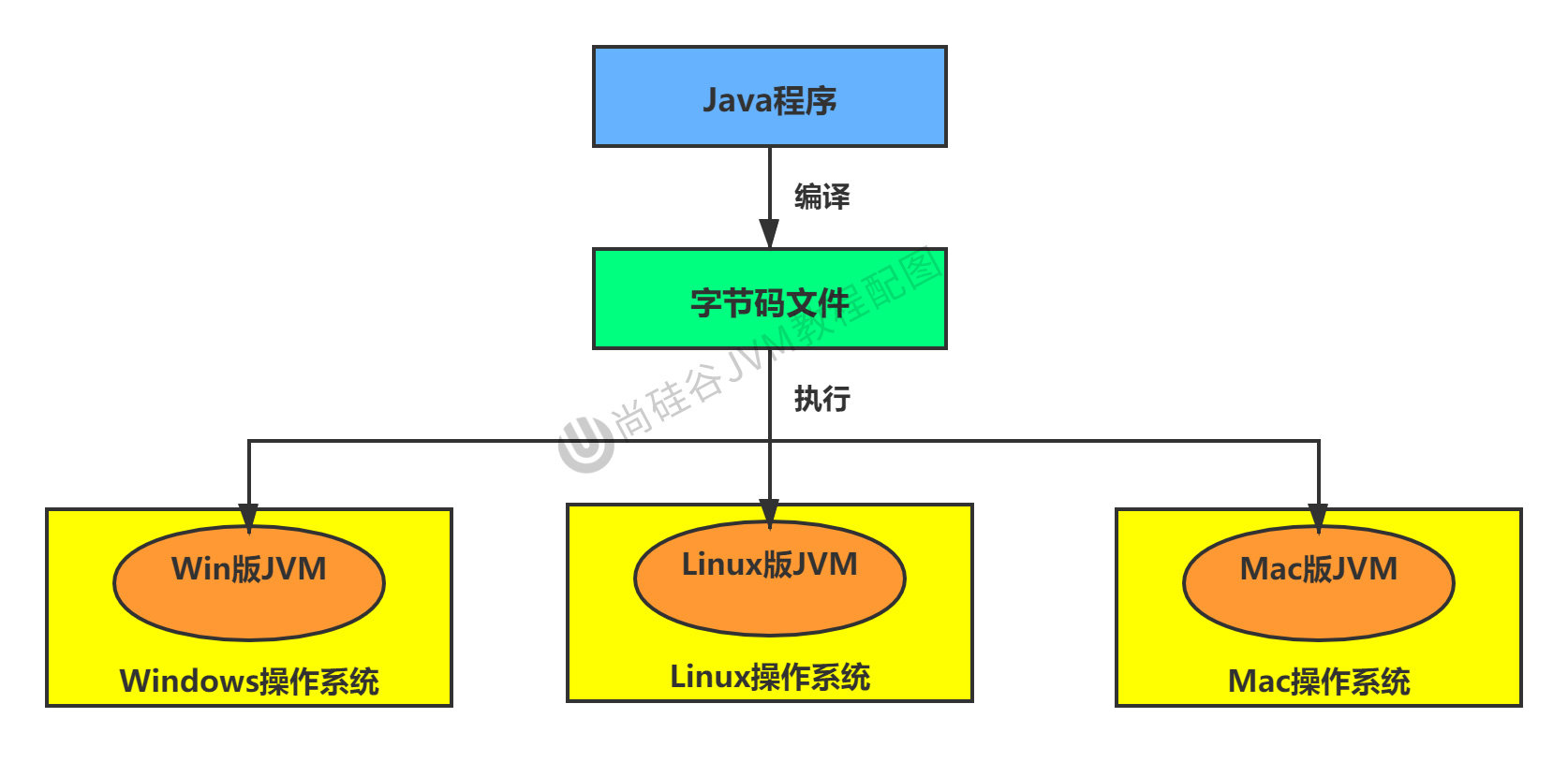
JVM 是 Java Virtual Machine 的缩写,即咱们经常提到的 Java 虚拟机。虚拟机是一种抽象化的计算机,有着自己完善的硬件架构,如处理器、堆栈等,具体有什么咱们不做了解。目前我们只需要知道想要运行 Java 文件,必须先通过一个叫 javac 的编译器,将代码编译成 class 文件,然后通过 JVM 把 class 文件解释成各个平台可以识别的机器码,最终实现跨平台运行代码。

每种机器上的解释器是不一样的,我们经常用的也就是 Windows 和 Linux 系统,这也是为什么 java 能够跨平台的原因。
运行时数据区域
Java 虚拟机在执行 Java 程序的过程中会把它所管理的内存划分为若干个不同的数据区域。这些区域都有各自的用途,以及创建和销毁的时间,有的区域随着虚拟机进程的启动而存在,有些区域则依赖用户线程的启动和结束而建立和销毁。
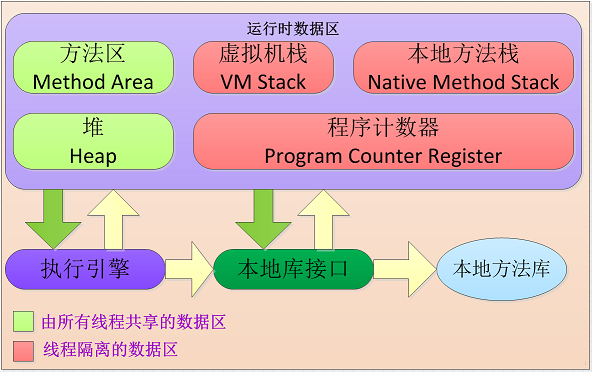
程序计数器
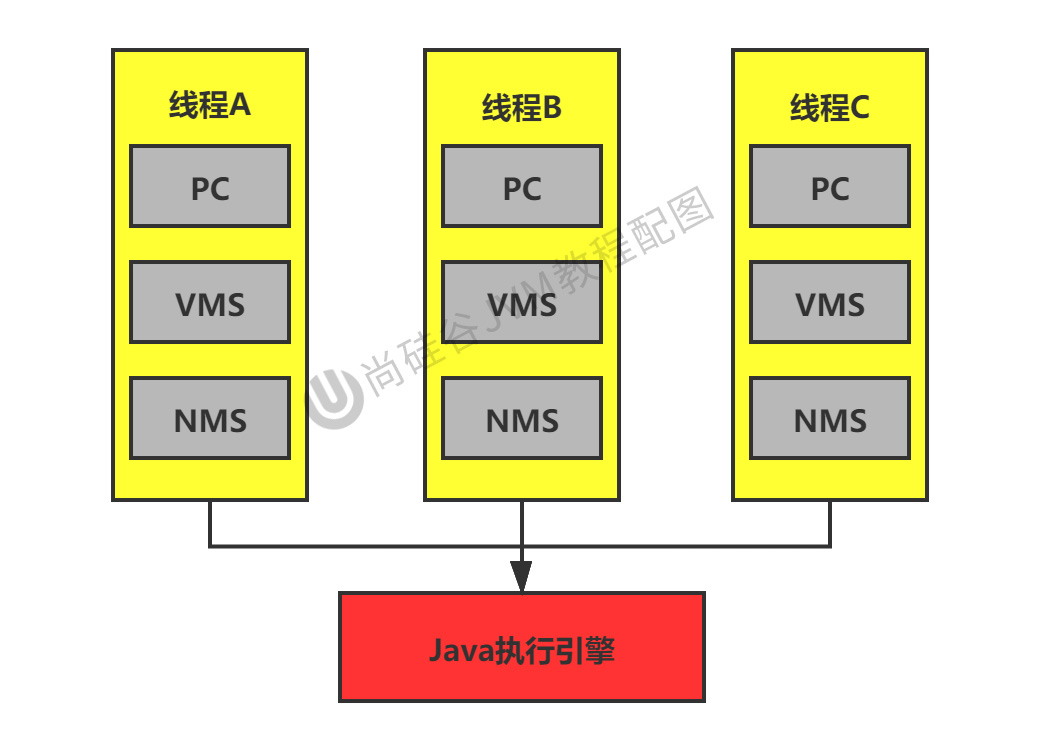
一块较小的内存空间,它可以看做是当前线程所执行的字节码的行号指示器,记录当前线程执行的进度。
每个线程都需要有自己独立的程序计数器,并且不能互相被干扰,否则就会影响到程序的正常执行次序。因此,可以这么说,程序计数器是每个线程所私有的。
提示
假如你此时正在做事件 A,当事件 A 进行到一半时你又要去做事件 B,此时你写了一张便条记录事件 A 的进度,然后就去做事件 B 了。当事件 B 进行到某一步后你又写了一张便条记录事件 B 的进度,然后回到事件 A 继续事件 A 的进度。
如果没有写便条,你就有可能会忘记上一个事件的进度。
Java 虚拟机栈
虚拟机栈描述的是 Java 方法执行的内存模型:每个方法在执行的同时都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。
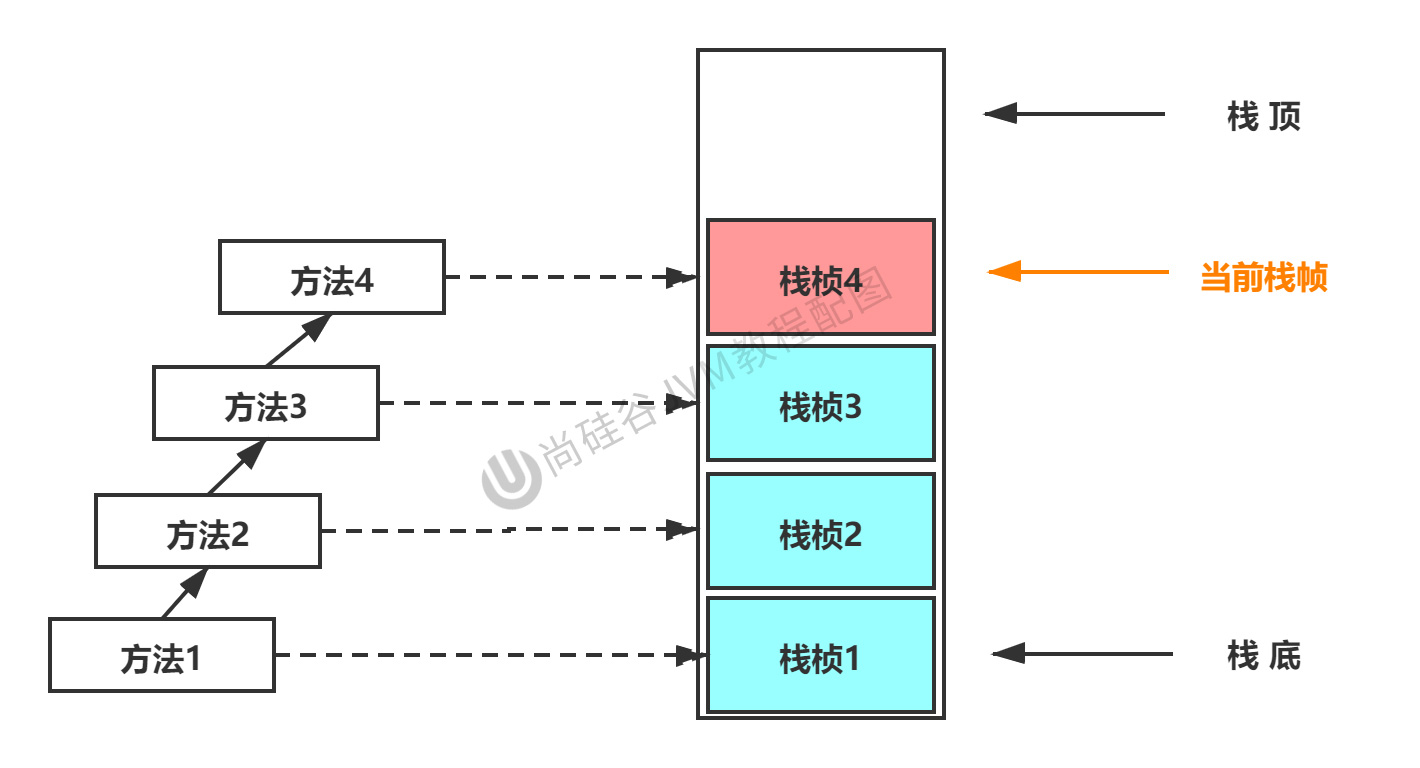
局部变量表存放了编译期可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference 类型)和 returnAddress 类型(指向了一条字节码指令的地址)。
局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在帧中分配多大的局部变量空间是完全确定的,在方法运行期间不会改变局部变量表的大小。

本地方法栈
虚拟机栈为虚拟机执行 Java 方法(也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。在虚拟机规范中对本地方法栈中方法使用的语言、使用方式与数据结构并没有强制规定。(可能是 C++ 也可能是其它编程语言)
Java 堆
Java 堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。
方法区(永久代)
方法区(Method Area)与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据,即存放静态文件,如 Java 类、方法等。
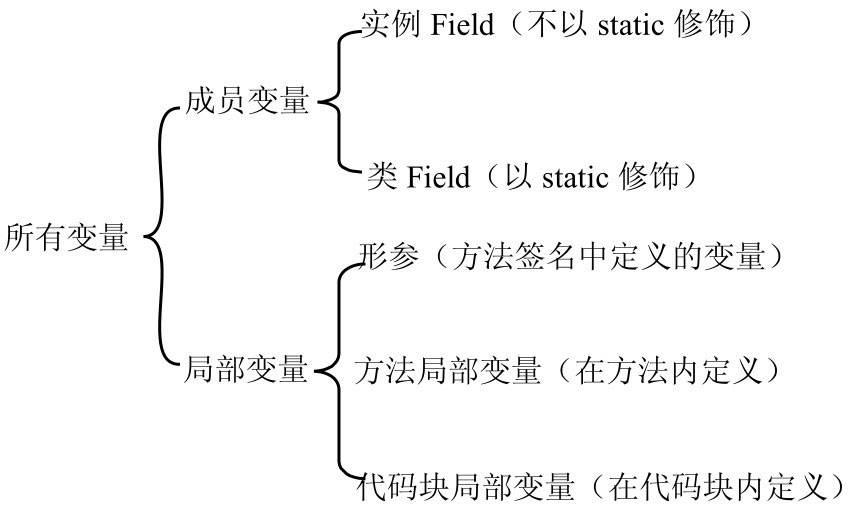
成员变量和局部变量
在 Java 语言中,根据定义变量位置的不同,可以将变量分成两大类:成员变量和局部变量。成员变量和局部变量的运行机制存在较大差异。
成员变量指的是在类范围里定义的变量;局部变量指的是在方法里定义的变量。
提示
不管是成员变量还是局部变量,都应该遵守相同的命名规则:从语法角度来看,只要是一个合法的标识符即可;但从程序可读性角度来看,应该是多个有意义的单词连缀而成,其中第一个单词首字母小写,后面每个单词首字母大写。
成员变量被分为类 Field 和实例 Field 两种,定义 Field 时没有 static 修饰的就是实例 Field,有 static 修饰的就是类 Field。
其中类 Field 从这个类的准备阶段起开始存在,直到系统完全销毁这个类,类 Field 的作用域与这个类的生存范围相同;而实例 Field 则从该类的实例被创建起开始存在,直到系统完全销毁这个实例,实例 Field 的作用域与对应实例的生存范围相同。
提示
一个类在使用之前要经过类加载、类验证、类准备、类解析、类初始化等几个阶段。
正是基于这个原因,我们把类 Field 和实例 Field 统称为成员变量,其中类 Field 可以理解为类成员变量,它作为类本身的一个成员,与类本身共存亡;实例 Field 则可理解为实例成员变量,它作为实例的一个成员,与实例共存亡。只要类存在,程序就可以访问该类的类 Field。
在程序中访问类 Field 通过如下语法:
类.类 Field
只要实例存在,程序就可以访问该实例的实例 Field。
在程序中访问实例 Field 通过如下语法:
实例.实例 Field
类 Field 也可以让该类的实例来访问。
实例.类 Field
但由于这个实例并不拥有这个类 Field,因此它访问的并不是这个实例的 Field,依然是访问它对应类的类 Field。
也就是说,如果通过一个实例修改了类 Field 的值,由于这个类 Field 并不属于它,而是属于它对应的类。
因此,修改的依然是类的类 Field,与通过该类来修改类 Field 的结果完全相同,这会导致该类的其他实例来访问这个类 Field 时也将获得这个被修改过的值。
下面程序定义了一个 Person 类,在这个 Person 类中定义两个成员变量,一个实例 Field:name,以及一个类 Field:eyeNum。程序还通过 PersonTest 类来创建 Person 实例,并分别通过 Person 类和 Person 实例来访问实例 Field 和类 Field。
class Person {
// 定义一个实例Field
public String name;
// 定义一个类Field
public static int eyeNum;
}
public class PersonTest {
public static void main(String[] args) {
// Person类已经初始化了,则eyeNum变量起作用了,输出0
System.out.println("Person的eyeNum类Field值:" + Person.eyeNum);
// 创建Person对象
Person p = new Person();
// 通过Person对象的引用p来访问Person对象name实例Field
// 并通过实例访问eyeNum类Field
System.out.println("p变量的name Field值是:" + p.name + "p对象的eyeNum Field值是:" + p.eyeNum);
// 直接为name实例Field赋值
p.name = "孙悟空";
// 通过p访问eyeNum类Field,依然是访问Person的eyeNum类Field
p.eyeNum = 2;
// 再次通过Person对象来访问name实例Field和eyeNum类Field
System.out.println("p变量的name Field值是:" + p.name + " p对象的eyeNum Field值是:" + p.eyeNum);
// 前面通过p修改了Person的eyeNum,此处的Person.eyeNum将输出2
System.out.println("Person的eyeNum类Field值:" + Person.eyeNum);
Person p2 = new Person();
// p2访问的eyeNum类Field依然引用Person类的,因此依然输出2
System.out.println("p2对象的eyeNum类Field值:" + p2.eyeNum);
}
}
成员变量无须显式初始化,只要为一个类定义了类 Field 或实例 Field,系统就会在这个类的准备阶段或创建该类的实例时进行默认初始化,成员变量默认初始化时的赋值规则与数组动态初始化时数组元素的赋值规则完全相同。
从上面程序运行结果来看,不难发现类 Field 的作用域比实例 Field 的作用域更大:实例 Field 随实例的存在而存在,而类 Field 则随类的存在而存在。
实例也可访问类 Field,同一个类的所有实例访问类 Field 时,实际上访问的是该类本身的同一个 Field,也就是说,访问了同一片内存区。
提示
正如前面提到的,Java 允许通过实例来访问 static 修饰的 Field 本身就是一个错误,因此读者以后看到通过实例来访问 static Field 的情形,都可以将它替换成通过类本身来访问 static Field 的情形,这样程序的可读性、明确性都会大大提高。
局部变量根据定义形式的不同,又可以被分为如下三种。
- 形参:在定义方法签名时定义的变量,形参的作用域在整个方法内有效。
- 方法局部变量:在方法体内定义的局部变量,它的作用域是从定义该变量的地方生效,到该方法结束时失效。
- 代码块局部变量:在代码块中定义的局部变量,这个局部变量的作用域从定义该变量的地方生效,到该代码块结束时失效。
与成员变量不同的是,局部变量除了形参之外,都必须显式初始化。
也就是说,必须先给方法局部变量和代码块局部变量指定初始值,否则不可以访问它们。
public class BlockTest {
public static void main(String[] args) {
{
// 定义一个代码块局部变量a
int a;
// 下面代码将出现错误,因为a变量还未初始化
// System.out.println("代码块局部变量a的值:" +a);
// 为a变量赋初始值,也就是进行初始化
a = 5;
System.out.println("代码块局部变量a的值:" + a);
}
// 下面试图访问的a变量并不存在
// System.out.println(a);
}
}
从上面代码中可以看出,只要离开了代码块局部变量所在的代码块,这个局部变量就立即被销毁,变为不可见。
对于方法局部变量,其作用域从定义该变量开始,直到该方法结束。
public class MethodLocalVariableTest {
public static void main(String[] args) {
// 定义一个方法局部变量a
int a;
// 下面代码将出现错误,因为a变量还未初始化
// System.out.printIn("方法局部变量a的值:" +a);
// 为a变量赋初始值,也就是进行初始化
a = 5;
System.out.println("方法局部变量a的值:" + a);
}
}
形参的作用域是整个方法体内有效,而且形参也无须显式初始化,形参的初始化在调用该方法时由系统完成,形参的值由方法的调用者负责指定。
当通过类或对象调用某个方法时,系统会在该方法栈区内为所有的形参分配内存空间,并将实参的值赋给对应的形参,这就完成了形参的初始化。
在同一个类里,成员变量的作用范围是整个类内有效,一个类里不能定义两个同名的成员变量,即使一个是类 Field,一个是实例 Field 也不行;一个方法里不能定义两个同名的局部变量,即使一个是方法局部变量,一个是代码块局部变量或者形参也不行。
Java 允许局部变量和成员变量同名,如果方法里的局部变量和成员变量同名,局部变量会覆盖成员变量,如果需要在这个方法里引用被覆盖的成员变量,则可使用 this(对于实例 Field)或类名(对于类 Field)作为调用者来限定访问成员变量。
public class VariableOverrideTest {
// 定义一个name实例Field
private String name = "李刚";
// 定义一个price类Field
private static double price = 78.0;
// 主方法,程序的入口
public static void main(String[] args) {
// 方法里的局部变量,局部变量覆盖成员变量
int price = 65;
// 直接访问price变量,将输出price局部变量的值:65
System.out.println(price);
// 使用类名作为price变量的限定
// 将输出price类Field的值:78.0
System.out.println(VariableOverrideTest.price);
// 运行info方法
new VariableOverrideTest().info();
}
public void info() {
// 方法里的局部变量,局部变量覆盖成员变量
String name = "孙悟空";
// 直接访问name变量,将输出name局部变量的值:"孙悟空"
System.out.println(name);
// 使用this来作为name变量的限定
// 将输出price实例Field的值:"李刚"
System.out.println(this.name);
}
}
成员变量
当系统加载类或创建该类的实例时,系统自动为成员变量分配内存空间,并在分配内存空间后,自动为成员变量指定初始值。
// 创建第一个Person对象
Person p1 = new Person();
// 创建第二个Person对象
Person p2 = new Person();
// 分别为两个Person对象的name Field赋值
p1.name = "张三";
p2.name = "孙悟空";
// 分别为两个Person对象的eyeNum Field赋值
p1.eyeNum = 2;
p2.eyeNum = 3;
当程序执行第一行代码 Person p1 = new Person(); 时,如果这行代码是第一次使用 Person 类,则系统通常会在第一次使用 Person 类时加载这个类,并初始化这个类。
在类的准备阶段,系统将会为该类的 类Field 分配内存空间,并指定默认初始值。

系统接着创建了一个 Person 对象,并把这个 Person 对象赋给 p1 变量,Person 对象里包含了名为 name 的 实例Field,实例Field 是在创建实例时分配内存空间并指定初始值的。
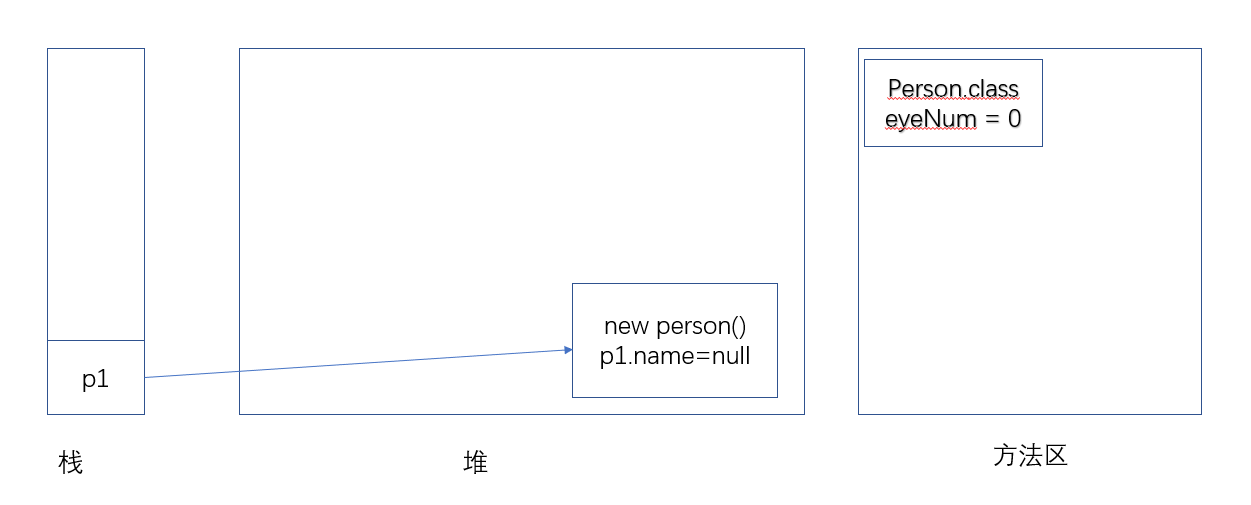
eyeNum类Field 并不属于 Person 对象,它是属于 Person 类的,所以创建第一个 Person 对象时并不需要为 eyeNum类Field 分配内存,系统只是为 name实例Field 分配了内存空间,并指定默认初始值:null。
接着执行 Person p2=new Person(); 代码创建第二个 Person 对象,此时因为 Person 类已经被加载了,所以不再需要对 Person 类进行初始化。
创建第二个 Person 对象与创建第一个 Person 对象并没有什么不同。
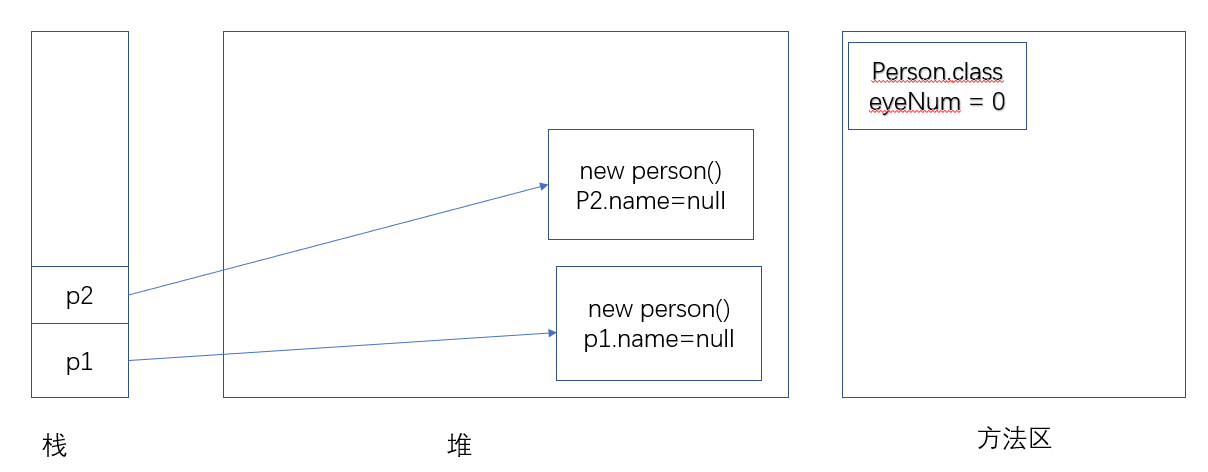
当程序执行 p1.name="张三"; 代码时,将为 p1 的 name实例Field 赋值,name实例Field 是属于单个 Person 实例的,因此修改第一个 Person 对象的 name实例Field 时仅仅与该对象有关,与 Person 类和其他 Person 对象没有任何关系。
同样,修改第二个 Person 对象的 name实例Field 时,也与 Person 类和其他 Person 对象无关。
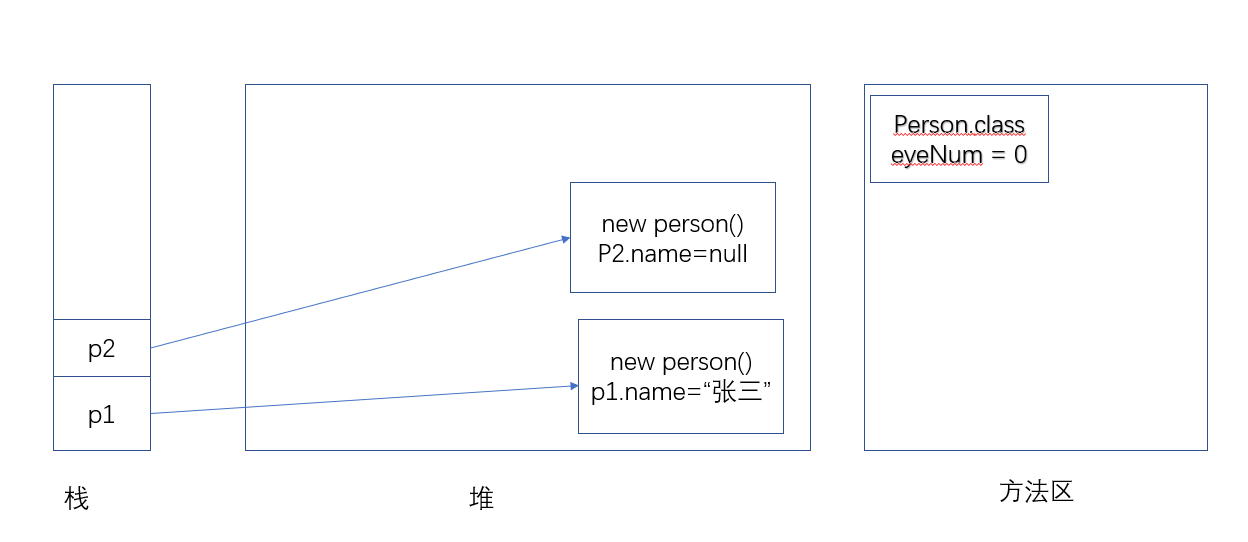
直到执行 p1.eyeNum=2; 代码时,此时通过 Person 对象来修改 Person 的 类Field,但是 Person 对象根本没有保存 eyeNum 这个 Field,所以通过 p1 访问的 eyeNum 类 Field,其实还是 Person 类的 eyeNum 类 Field。因此,此时修改的是 Person 类的 eyeNum 类 Field。
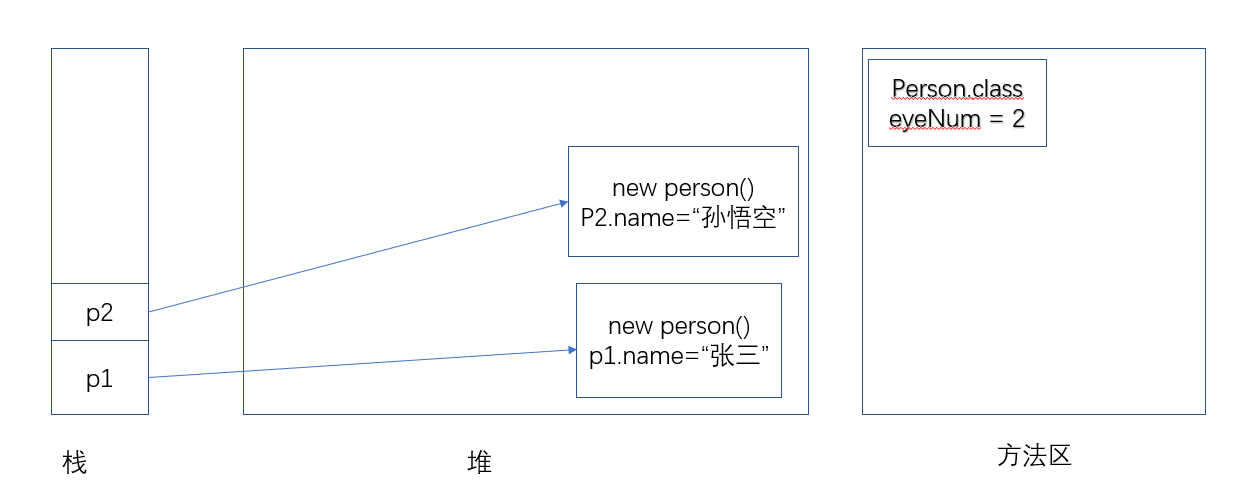
提示
不管通过哪个 Person 实例来访问 eyeNum Field,本质其实还是通过 Person 类来访问 eyeNum Field,它们所访问的是同一块内存。
当程序需要访问 类Field 时,尽量使用类作为主调,而不要使用对象作为主调,这样可以避免程序产生歧义,提高程序的可读性。
局部变量
局部变量定义后,必须经过显式初始化后才能使用,系统不会为局部变量执行初始化。
定义局部变量后,系统并未为这个变量分配内存空间,直到等到程序为这个变量赋初始值时,系统才会为局部变量分配内存,并将初始值保存到这块内存中。
局部变量不属于任何类或实例,因此它总是保存在其所在方法的栈内存中。如果局部变量是基本类型的变量,则直接把这个变量的值保存在该变量对应的内存中;如果局部变量是一个引用类型的变量,则这个变量里存放的是地址,通过该地址引用到该变量实际引用的对象或数组。
隐藏和封装
封装(Encapsulation)是面向对象的三大特征之一(另外两个是继承和多态),它指的是将对象的状态信息隐藏在对象内部,不允许外部程序直接访问对象内部信息,而是通过该类所提供的方法来实现对内部信息的操作和访问。
相关信息
封装,保证内部结构的安全,屏蔽复杂,暴露简单。
生活中的封装:汽车,我们会开车但看不到汽车的内部结构。手机、电脑等。
封装是面向对象编程语言对客观世界的模拟,客观世界里的 Field 都是被隐藏在对象内部的,外界无法直接操作和修改。
对一个类或对象实现良好的封装,可以实现以下目的。
- 隐藏类的实现细节。
- 让使用者只能通过事先预定的方法来访问数据,从而可以在该方法里加入控制逻辑,限制对 Field 的不合理访问。
- 可进行数据检查,从而有利于保证对象信息的完整性。
- 便于修改,提高代码的可维护性。为了实现良好的封装,需要从两个方面考虑。
- 将对象的 Field 和实现细节隐藏起来,不允许外部直接访问。
- 把方法暴露出来,让方法来控制对这些 Field 进行安全的访问和操作。
使用访问控制符
Java 提供了 3 个访问控制符:private、protected 和 public,分别代表了 3 个访问控制级别,另外还有一个不加任何访问控制符的访问控制级别,提供了 4 个访问控制级别。

4 个访问控制级别中的 default 并没有对应的访问控制符,当不使用任何访问控制符来修饰类或类成员时,系统默认使用该访问控制级别。
private(当前类访问权限):
如果类里的一个成员(包括 Field、方法和构造器等)使用
private访问控制符来修饰,则这个成员只能在当前类的内部被访问。很显然,这个访问控制符用于修饰 Field 最合适,使用它来修饰 Field 就可以把 Field 隐藏在该类的内部。
default(包访问权限):
如果类里的一个成员(包括 Field、方法和构造器等)或者一个外部类不使用任何访问控制符修饰,我们就称它是包访问权限,
default访问控制的成员或外部类可以被相同包下的其他类访问。
protected(子类访问权限):
如果一个成员(包括 Field、方法和构造器等)使用
protected访问控制符修饰,那么这个成员既可以被同一个包中的其他类访问,也可以被不同包中的子类访问。在通常情况下,如果使用protected来修饰一个方法,通常是希望其子类来重写这个方法。
public(公共访问权限):
这是一个最宽松的访问控制级别,如果一个成员(包括Field、方法和构造器等)或者一个外部类使用
public访问控制符修饰,那么这个成员或外部类就可以被所有类访问,不管访问类和被访问类是否处于同一个包中,是否具有父子继承关系。
| 访问控制符 | 当前类 | 同一包内 | 子孙类 | 其它包 |
|---|---|---|---|---|
| public | Y | Y | Y | Y |
| protected | Y | Y | Y | N |
| default | Y | Y | N | N |
| private | Y | N | N | N |
对于局部变量而言,其作用域就是它所在的方法,不可能被其他类访问,因此不能使用访问控制符来修饰。
对于外部类而言,它也可以使用访问控制符修饰,但外部类只能有两种访问控制级别:public 和默认,外部类不能使用 private 和 protected 修饰,因为外部类没有处于任何类的内部,也就没有其所在类的内部、所在类的子类两个范围,因此 private 和 protected 访问控制符对外部类没有意义。
提示
如果一个 Java 源文件里定义的所有类都没有使用 public 修饰,则这个 Java 源文件的文件名可以是一切合法的文件名;但如果一个 Java 源文件里定义了一个 public 修饰的类,则这个源文件的文件名必须与 public 修饰的类的类名相同。
封装步骤:
private关键字修饰,表私有的,修饰的所有数据类型只能在本类当中访问。- 对外提供简单的操作入口
setter、getter方法。 setter、getter方法都不带有static,都是实例方法。
public class Person {
// 将Field使用private修饰,将这些Field隐藏起来
private String name;
private int age;
// 提供方法来操作name Field
public void setName(String name) {
// 执行合理性校验,要求用户名必须在2~6位之间
if (name.length() > 6 || name.length() < 2) {
System.out.println("您设置的人名不符合要求");
return;
} else {
this.name = name;
}
}
public String getName() {
return this.name;
}
// 提供方法来操作age Field
public void setAge(int age) {
// 执行合理性校验,要求用户年龄必须在0~100之间
if (age > 100 || age < 0) {
System.out.println("您设置的年龄不合法");
return;
} else {
this.age = age;
}
}
public int getAge() {
return this.age;
}
}
提示
Java 类里 Field 的 setter 和 getter 方法有非常重要的意义。
例如,某个类里包含了一个名为 abc 的 Field,则其对应的 setter 和 getter 方法名应为 setAbc 和 getAbc(即将原 Field 名的首字母大写,并在前面分别增加 set 和 get 动词,就变成 setter 和 getter 方法名)。
如果一个 Java 类的每个 Field 都被使用 private 修饰,并为每个 Field 都提供了 public 修饰 setter 和 getter 方法,那么这个类就是一个符合 JavaBean 规范的类。
public class PersonTest {
public static void main(String[] args) {
Person p = new Person();
// 因为age Field已被隐藏,所以下面语句将出现编译错误
// p.age = 1000;
// 下面语句编译不会出现错误,但运行时将提示“您设置的年龄不合法”
// 程序不会修改p的age Field
p.setAge(1000);
// 访问p的age Field也必须通过其对应的getter方法
// 因为上面从未成功设置p的age Field,故此处输出0
System.out.println("未能设置age Field时:" + p.getAge());
// 成功修改p的age Field
p.setAge(30);
// 因为上面成功设置了p的age Field,故此处输出30
System.out.println("成功设置age Field后:" + p.getAge());
// 不能直接操作p的name Field,只能通过其对应的setter方法
// 因为"李刚"字符串长度满足2~6,所以可以成功设置
p.setName("李刚");
System.out.printIn("成功设置name Field后:" + p.getName());
}
}
相关信息
一个类常常就是一个小的模块,我们应该只让这个模块公开必须让外界知道的内容,而隐藏其他一切内容。
进行程序设计时,应尽量避免一个模块直接操作和访问另一个模块的数据,模块设计追求高内聚(尽可能把模块的内部数据、功能实现细节隐藏在模块内部独立完成,不允许外部直接干预)、低耦合(仅暴露少量的方法给外部使用)。
正如我们日常常见的内存条,内存条里的数据及其实现细节被完全隐藏在内存条里面,外部设备(如主机板)只能通过内存条的金手指(提供一些方法供外部调用)来和内存条进行交互。
关于访问控制符的使用,存在如下几条基本原则。
- 类里的绝大部分 Field 都应该使用
private修饰,只有一些static修饰的、类似全局变量的 Field,才可能考虑使用public修饰。除此之外,有些方法只是用于辅助实现该类的其他方法,这些方法被称为工具方法,工具方法也应该使用private修饰。- 如果某个类主要用做其他类的父类,该类里包含的大部分方法可能仅希望被其子类重写,而不想被外界直接调用,则应该使用
protected修饰这些方法。- 希望暴露出来给其他类自由调用的方法应该使用
public修饰。因此,类的构造器通过使用public修饰,从而允许在其他地方创建该类的实例。因为外部类通常都希望被其他类自由使用,所以大部分外部类都使用public修饰。
package
package 机制提供了类的多层命名空间,用于解决类的命名冲突、类文件管理等问题。
Java 允许将一组功能相关的类放在同一个 package 下,从而组成逻辑上的类库单元。
package 是一个关键字,后面加包名,例如:package com.bjpowernode.javase.chapter; package 语句只允许出行在 java 源代码的第一行:
package packageName;
一旦在 Java 源文件中使用了这个 package 语句,就意味着该源文件里定义的所有类都属于这个包。
位于包中的每个类的完整类名都应该是包名和类名的组合,如果其他人需要使用该包下的类,也应该使用包名加类名的组合。
package lee;
public class Hello {
public static void main(String[] args) {
System.out.println("Hello World!");
}
}
上面程序表明把 Hello 类放在 lee 包空间下。把上面源文件保存在任意位置,使用如下命令来编译这个 Java 文件:
javac -d . Hello.java
-d 选项用于设置编译生成 class 文件的保存位置,这里指定将生成的 class 文件放在当前路径(.就代表当前路径)下。
使用该命令编译该文件后,发现当前路径下并没有 Hello.class 文件,而是在当前路径下多了一个名为 lee 的文件夹,该文件夹下则有一个 Hello.class 文件。
假设某个应用中包含两个 Hello 类,Java 通过引入包机制来区分两个不同的 Hello 类。不仅如此,这两个 Hello 类还对应两个 Hello.class 文件,它们在文件系统中也必须分开存放才不会引起冲突。
所以 Java 规定:位于包中的类,在文件系统中也必须有与包名层次相同的目录结构。
当虚拟机要装载 lee.Hello 类时,它会依次搜索 CLASSPATH 环境变量所指定的系列路径,查找这些路径下是否包含 lee 路径,并在 lee 路径下查找是否包含 Hello.class 文件。
相关信息
为 Java 类添加包必须在 Java 源文件中通过 package 语句指定,单靠目录名是没法指定的。Java 的包机制需要两个方面保证:
① 源文件里使用 package 语句指定包名;
② class 文件必须放在对应的路径下。
同一个包下的类可以自由访问,例如下面的 HelloTest 类,如果把它也放在 lee 包下,则这个 HelloTest 类可以直接访问 Hello 类,无须添加包前缀。
package lee;
public class HelloTest {
public static void main(String[] args) {
// 直接访问相同包下的另一个类,无须使用包前缀
Hello h = new Hello();
}
}
在 lee 包下再定义一个 sub 子包,并在该包下定义一个 Apple 空类。
package lee.sub;
public class Apple{}
对于上面的 lee.sub.Apple 类,位于 lee.sub 包下,与 lee.HelloTest 类和 lee.Hello 类不再处于同一个包下,因此使用 lee.sub.Apple 类时就需要使用该类的全名(即包名加类名)。
例如在 lee.HelloTest 类中创建 lee.sub.Apple 类的对象,则需要采用如下代码:
//调用构造器时需要在构造器前增加包前缀
lee.sub.Apple a = new lee.sub.Apple();
为了简化编程,Java 引入了 import 关键字,import 可以向某个 Java 文件中导入指定包层次下某个类或全部类,import 语句应该出现在 package 语句(如果有的话)之后、类定义之前。
一个 Java 源文件只能包含一个 package 语句,但可以包含多个 import 语句,多个 import 语句用于导入多个包层次下的类。
import package.subpackage...ClassName;
导入前面提到的 lee.sub.Apple 类:
import lee.sub.Apple;
导入指定包下全部类的用法如下:
import package.subpackage...*
上面 import 语句中的星号 * 只能代表类,不能代表包。
使用 import lee.*; 语句时,它表明导入 lee 包下的所有类,即 Hello 类和 HelloTest 类,而 lee 包下 sub 子包内的类则不会被导入。
一旦在 Java 源文件中使用 import 语句来导入指定类,在该源文件中使用这些类时就可以省略包前缀,不再需要使用类全名。
package lee;
//使用import导入lee.sub.Apple类import lee.sub.Apple;
public class HelloTest {
public static void main(String[] args) {
Hello h = new Hello();// 使用类全名的写法
lee.sub.Apple a = new lee.sub.Apple();
// 如果使用import语句来导入Apple类,就可以不再使用类全名了
Apple aa = new Apple();
}
}
提示
Java 默认为所有源文件导入 java.lang 包下的所有类,因此在 Java 程序中使用 String、System 类时都无须使用 import 语句来导入这些类。
但对于数组的 Arrays 类,其位于 java.util 包下,则必须使用 import 语句来导入该类。
在一些极端的情况下,import 语句也帮不了我们,我们只能在源文件中使用类全名。
import java.util.*;
import java.sql.*;
如果在程序中需要使用 Date 类,则会引起如下编译错误:
HelloTest.java:25:对 Date 的引用不明确,
java.sql中的类java.sql.Date 和 java.util中的类java.util.Date 都匹配
import 语句导入的 java.sql 和 java.util 包下都包含了 Date 类,在这种情况下,如果需要指定包下的 Date 类,则只能使用该类的全名。
//为了让引用更加明确,即使使用了import语句,也还是需要使用类的全名
java.sql.Date d = new java.sql.Date();
JDK 1.5 以后更是增加了一种静态导入的语法,它用于导入指定类的某个静态 Field、方法或全部的静态 Field、方法。
静态导入使用 import static 语句,静态导入也有两种语法,分别用于导入指定类的单个静态 Field、方法和全部静态 Field、方法,其中导入指定类的单个静态 Field、方法的语法格式如下:
import static package.subpackage...ClassName.fieldNamelme | methodName;
上面语法导入 package.subpackage...ClassName 类中名为 fieldName 的静态 Field 或者名为 methodName 的静态方法。
例如,可以使用 import static java.lang.System.out; 语句来导入 java.lang.System 类的 out 静态 Field。
导入指定类的全部静态 Field、方法的语法格式如下:
import static package.subpackage...ClassName.*;
星号只能代表静态 Field 或方法名。
提示
使用 import 可以省略写包名;而使用 import static 则可以连类名都省略。
用 import static 语句来导入 java.lang.System 类下的全部静态 Field,从而可以将程序简化成如下形式。
import static java.lang.System.*;
import static java.lang.Math.*;
public class StaticlmportTest {
public static void main(String[] args) {
// out是java.lang.System类的静态Field,代表标准输出
// PI是java.lang.Math类的静态Field,表示Tt常量
out.println(PI);
// 直接调用Math类的sqrt静态方法
out.println(sqrt(256));
}
}
深入构造器
构造器是一个特殊的方法,这个特殊方法用于创建实例时执行初始化。构造器是创建对象的重要途径(即使使用工厂模式、反射等方式创建对象,其实质依然是依赖于构造器),因此,Java 类必须包含一个或一个以上的构造器。
使用构造器执行初始化
当创建一个对象时,系统为这个对象的 Field 进行默认初始化,这种默认的初始化把所有基本类型的 Field 设为 0(对数值型 Field)或 false(对布尔型 Field),把所有引用类型的 Field 设为 null。
如果想改变这种默认的初始化,想让系统创建对象时就为该对象的 Field 显式指定初始值,就可以通过构造器来实现。
提示
如果程序员没有为 Java 类提供任何构造器,则系统会为这个类提供一个无参数的构造器,这个构造器的执行体为空,不做任何事情。无论如何,Java 类至少包含一个构造器。
通过构造器就可以让程序员进行自定义的初始化操作。
public class ConstructorTest {
public String name;
public int count;
//提供自定义的构造器,该构造器包含两个参数
public ConstructorTest(String name, int count) {
//构造器里的this代表它进行初始化的对象
//下面两行代码将传入的2个参数赋给this代表对象
// 的name和count两个Field
this.name = name;
this.count = count;
}
public static void main(String[] args) {
//使用自定义的构造器来创建对象
//系统将会对该对象执行自定义的初始化
ConstructorTest tc = new ConstructorTest("疯狂Java讲义", 90000);
//输出ConstructorTest对象的name和count两个Field
System.out.println(tc.name);
System.out.println(tc.count);
}
}
运行上面程序,将看到输出 ConstructorTest 对象时,它的 name 实例 Field 不再是 null,而且 count 实例 Field 也不再是 0。
构造器是创建 Java 对象的途径,但不是说构造器完全负责创建 Java 对象,通过 new 关键字调用构造器时,构造器也确实返回了该类的对象,但这个对象并不是完全由构造器负责创建的。
实际上,当程序员调用构造器时,系统会先为该对象分配内存空间,并为这个对象执行默认初始化,这个对象已经产生了——这些操作在构造器执行之前就都完成了。
当系统开始执行构造器的执行体之前,系统已经创建了一个对象,只是这个对象还不能被外部程序访问,只能在该构造器中通过 this 来引用。
当构造器的执行体执行结束后,这个对象作为构造器的返回值被返回,通常还会赋给另一个引用类型的变量,从而让外部程序可以访问该对象。
一旦程序员提供了自定义的构造器,系统就不再提供默认的构造器,因此上面的 ConstructorTest 类不能再通过 new ConstructorTest() 代码来创建实例,因为该类不再包含无参数的构造器。
如果希望该类保留无参数的构造器,或者希望有多个初始化过程,则可以为该类提供多个构造器。如果一个类里提供了多个构造器,就形成了构造器的重载。
因为构造器主要用于被其他方法调用,用以返回该类的实例,因而通常把构造器设置成 public 访问权限,从而允许系统中任何位置的类来创建该类的对象。
除非在一些极端的情况下,我们需要限制创建该类的对象,可以把构造器设置成其他访问权限,例如设置为 protected,主要用于被其子类调用;把其设置为 private,阻止其他类创建该类的实例。
提示
通常建议为 Java 类保留无参数的默认构造器。因此,如果为一个类编写了有参数的构造器,则通常建议为该类额外提供一个无参数的构造器。
public class Student{
// 学号
int no;
// 姓名
String name;
// 年龄
int age;
// 性别
boolean sex = false;
// 住址
String addr;
// 当前的Student这个类当中并没有定义任何构造方法。
// 但是系统实际上会自动给Student类提供一个无参数的构造方法。
// 将无参数的构造方法(缺省构造器)写出来
public Student(){}
public Student(int no, String name){}
}
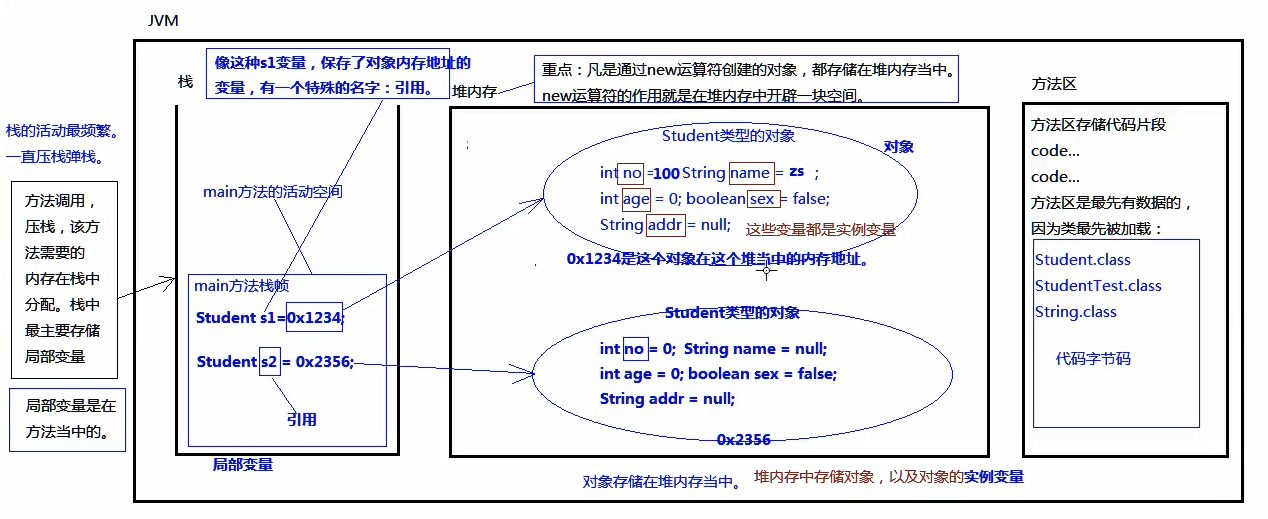
创建对象
public class ConstructorTest01{
public static void main(String[] args){
// 调用另一个有参数的构造方法。
Student s1 = new Student(100, zs);
System.out.println(s2); //Student@5caf905d
// 创建Student类型的对象
Student s2 = new Student();
// 输出“引用”
//只要输出结果不是null,说明这个对象一定是创建完成了。
System.out.println(s1); //Student@54bedef2
}
}
内存结构图
构造器重载
同一个类里具有多个构造器,多个构造器的形参列表不同,即被称为构造器重载。构造器重载允许 Java 类里包含多个初始化逻辑,从而允许使用不同的构造器来初始化 Java 对象。
构造器重载和方法重载基本相似:要求构造器的名字相同,而因为构造器必须与类名相同,所以同一个类的所有构造器名肯定相同。为了让系统能区分不同的构造器,多个构造器的参数列表必须不同。
public class ConstructorOverload {
public String name;
public int count;
// 提供无参数的构造器
public ConstructorOverload() {
}
// 提供带两个参数的构造器
// 对该构造器返回的对象执行初始化
public ConstructorOverload(String name, int count) {
this.name = name;
this.count = count;
}
public static void main(String[] args) {
// 通过无参数构造器创建ConstructorOverload对象
ConstructorOverload oc1 = new ConstructorOverload();
// 通过有参数构造器创建ConstructorOverload对象
ConstructorOverload oc2 = new ConstructorOverload("轻量级Java EE企业应用实战", 300000);
System.out.println(oc1.name + "" + oc1.count);
System.out.println(oc2.name + " " + oc2.count);
}
}
ConstructorOverload 类提供了两个重载的构造器,两个构造器的名字相同,但形参列表不同。系统通过 new 调用构造器时,系统将根据传入的实参列表来决定调用哪个构造器。
如果系统中包含了多个构造器,其中一个构造器的执行体里完全包含另一个构造器的执行体,如图。
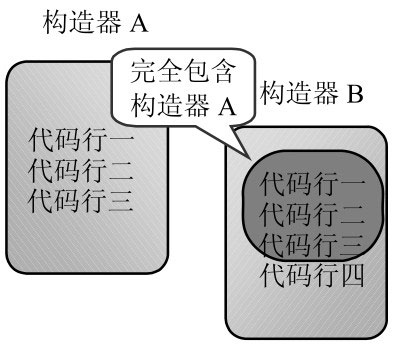
构造器 B 完全包含了构造器 A。对于这种完全包含的情况,如果是两个方法之间存在这种关系,则可在方法 B 中调用方法 A。
但构造器不能直接被调用,构造器必须使用 new 关键字来调用。但一旦使用 new 关键字来调用构造器,将会导致系统重新创建一个对象。
为了在构造器 B 中调用构造器 A 中的初始化代码,又不会重新创建一个 Java 对象,可以使用 this 关键字来调用相应的构造器。
public class Apple {
public String name;
public String color;
public double weight;
public Apple() {
}
// 两个参数的构造器
public Apple(String name, String color) {
this.name = name;
this.color = color;
}
// 三个参数的构造器
public Apple(String name, String color, double weight) {
// 通过this调用另一个重载的构造器的初始化代码
this(name, color);
// 下面this引用该构造器正在初始化的Java对象
this.weight = weight;
}
}
使用 this 调用另一个重载的构造器只能在构造器中使用,而且必须作为构造器执行体的第一条语句。使用 this 调用重载的构造器时,系统会根据 this 后括号里的实参来调用形参列表与之对应的构造器。
类的继承
承是面向对象的三大特征之一,也是实现软件复用的重要手段。Java 的继承具有单继承的特点,每个子类只有一个直接父类。
继承的特点
Java 的继承通过 extends 关键字来实现,实现继承的类被称为子类,被继承的类被称为父类,有的也称其为基类、超类。
Java 里子类继承父类的语法格式如下:
修饰符 class SubClass extends SuperClass {
// 类定义部分
}
定义子类的语法非常简单,只需在原来的类定义上增加 extends SuperClass 即可,即表明该子类继承了 SuperClass 类。
为什么国内把 extends 翻译为“继承”呢?除了与历史原因有关之外,把 extends 翻译为“继承”也是有其理由的:子类扩展了父类,将可以获得父类的全部 Field 和方法,这与汉语中的继承(子辈从父辈那里获得一笔财富称为继承)具有很好的类似性。值得指出的是,Java 的子类不能获得父类的构造器。
public class Fruit {
public double weight;
public void info() {
System.out.println("我是一个水果!重" + weight + "g! ");
}
}
public class Apple extends Fruit {
public static void main(String[] args) {
//创建Apple对象
Apple a = new Apple();
//Apple对象本身没有weight Field
// 因为Apple的父类有weight Field,也可以访问Apple对象的Field
a.weight = 56;
//调用Apple对象的info方法
a.info();
}
}
Apple 类本来只是一个空类,它只包含了一个 main 方法,但程序中创建了 Apple 对象之后,可以访问该 Apple 对象的 weight 实例 Field 和 info() 方法,这表明 Apple 对象也具有了 weight 实例 Field 和 info() 方法,这就是继承的作用。
Java 语言每个类最多只有一个直接父类。下面代码将会引起编译错误。
class SubClass extends Base1, Base2, Base3{...}
Java 类只能有一个直接父类,实际上,Java 类可以有无限多个间接父类。
class Apple extends Fruit{...}
class Fruit extends Plant{...}
定义一个 Java 类时并未显式指定这个类的直接父类,则这个类默认扩展 java.lang.Object 类,因此,java.lang.Object 类是所有类的父类,要么是其直接父类,要么是其间接父类。
因此所有的 Java 对象都可调用 java.lang.Object 类所定义的实例方法。
重写父类的方法
大部分时候,子类总是以父类为基础,额外增加新的 Field 和方法。但有一种情况例外:子类需要重写父类的方法。
例如鸟类都包含了飞翔方法,其中鸵鸟是一种特殊的鸟类,鸵鸟也是鸟的子类,它也将从鸟类获得飞翔方法,但这个飞翔方法明显不适合鸵鸟,为此,鸵鸟需要重写鸟类的方法。
public class Bird {
// Bird类的fly方法
public void fly() {
System.out.println("我在天空里自由自在地飞翔...");
}
}
下面再定义一个 Ostrich 类,这个类扩展了 Bird 类,重写了 Bird 类的 fly 方法。
public class Ostrich extends Bird {
// 重写Bird类的fly方法
public void fly() {
System.out.println("我只能在地上奔跑...");
}
public static void main(String[] args) {
// 创建Ostrich对象
Ostrich os = new Ostrich();
// 执行Ostrich对象的fly方法,将输出"我只能在地上奔跑..."
os.fly();
}
}
这种子类包含与父类同名方法的现象被称为方法重写,也被称为方法覆盖 Override。可以说子类重写了父类的方法,也可以说子类覆盖了父类的方法。
方法的重写要遵循“两同两小一大”规则:
两同:方法名相同、形参列表相同;
两小:子类方法返回值类型应比父类方法返回值类型更小或相等(基本数据类型必须相等,引用数据类型需要小于或等于父类),子类方法声明抛出的异常类应比父类方法声明抛出的异常类更小或相等;
一大:子类方法的访问权限应比父类方法的访问权限更大或相等。
覆盖方法和被覆盖方法要么都是类方法,要么都是实例方法,不能一个是类方法,一个是实例方法。
如下代码将会引发编译错误。
class BaseClass {
public static void test() {...}
}
class SubClass extends BaseClass {
public void test() {...}
}
当子类覆盖了父类方法后,子类的对象将无法访问父类中被覆盖的方法,但可以在子类方法中调用父类中被覆盖的方法。
如果需要在子类方法中调用父类中被覆盖的方法,则可以使用 super(被覆盖的是实例方法)或者父类类名(被覆盖的是类方法)作为调用者来调用父类中被覆盖的方法。
如果父类方法具有 private 访问权限,则该方法对其子类是隐藏的,子类无法访问该方法,如果子类中定义了一个与父类 private 方法具有相同的方法名、相同的形参列表、相同的返回值类型的方法,则不是重写,只是在子类中重新定义了一个新方法。
class BaseClass {
// test方法是private访问权限,子类不可访问该方法
private void test() {..}
}
class SubClass extends BaseClass {
// 此处并不是方法重写,所以可以增加static关键字
public static void test() {...}
}
super 限定
如果需要在子类方法中调用父类被覆盖的实例方法,则可使用 super 限定来调用父类被覆盖的实例方法。为上面的 Ostrich 类添加一个方法,在这个方法中调用 Bird 类中被覆盖的 fly 方法。
public void callOverridedMethod(){
// 在子类方法中通过super显式调用父类被覆盖的实例方法
super.fly();
}
super 是 Java 提供的一个关键字,super 用于限定该对象调用它从父类继承得到的 Field 或方法。
正如 this 不能出现在 static 修饰的方法中一样,super 也不能出现在 static 修饰的方法中。
static 修饰的方法是属于类的,该方法的调用者可能是一个类,而不是对象,因而 super 限定也就失去了意义。
如果在构造器中使用 super,则 super 用于限定该构造器初始化的是该对象从父类继承得到的 Field,而不是该类自己定义的 Field。
如果子类定义了和父类同名的 Field,则会发生子类 Field 隐藏父类 Field 的情形。
在正常情况下,子类里定义的方法直接访问该 Field 默认会访问到子类中定义的 Field,无法访问到父类中被隐藏的 Field。
在子类定义的实例方法中可以通过 super 来访问父类中被隐藏的 Field。
public class SubClass extends BaseClass {
public int a = 7;
public void accessOwner() {
System.out.println(a);
}
public void accessBase() {
// 通过super来限定访问从父类继承得到的a Field
System.out.println(super.a);
}
public static void main(String[] args) {
SubClass sc = new SubClass();// 输出7
sc.accessOwner();// 输出5
sc.accessBase();
}
}
当系统创建了 SubClass 对象时,实际上会为 SubClass 对象分配两块内存,一块用于存储在 SubClass 类中定义的 a Field,一块用于存储从 BaseClass 类继承得到的 a Field。
如果子类里没有包含和父类同名的 Field,那么在子类实例方法中访问该 Field 时,则无须显式使用 super 或父类名作为调用者。
如果在某个方法中访问名为 a 的 Field,但没有显式指定调用者,则系统查找 a 的顺序为:
- 查找该方法中是否有名为
a的局部变量;- 查找当前类中是否包含名为
a的 Field;- 查找
a的直接父类中是否包含名为a的 Field,依次上溯a的所有父类,直到java.lang.Object类,如果最终不能找到名为a的 Field,则系统出现编译错误。
如果被覆盖的是类 Field,在子类的方法中则可以通过父类名作为调用者来访问被覆盖的类 Field。
提示
当系统创建一个 Java 对象时,如果该 Java 类有两个父类(一个直接父类 A,一个间接父类 B),假设 A 类中定义了 2 个实例变量,B 类中定义了 3 个实例变量,当前类中定义了 2 个实例变量,那么这个 Java 对象将会保存 2+3+2 个实例变量。
如果在子类里定义了与父类中已有变量同名的变量,那么子类中定义的变量会隐藏父类中定义的变量。注意不是完全覆盖,因此系统在创建子类对象时,依然会为父类中定义的、被隐藏的变量分配内存空间。
因为子类中定义与父类中同名的实例变量并不会完全覆盖父类中定义的实例变量,它只是简单地隐藏了父类中的实例变量,所以会出现如下特殊的情形。
class Parent {
//①
public String tag = "疯狂Java讲义";
}
class Derived extends Parent {
//②
// 定义一个私有的tag实例变量来隐藏父类的tag实例变量
private String tag = "轻量级Java EE企业应用实战";
}
public class HideTest {
public static void main(String[] args) {
Derived d = new Derived();
// 程序不可访问d的私有变量tag,所以下面语句将引起编译错误
// System.out.printIn(d.tag);
//③
// 将d变量显式地向上转型为Parent后,即可访问tag实例变量
//④
// 程序将输出:“疯狂Java讲义”
System.out.println(((Parent)d).tag);
}
}
程序的入口 main 方法中先创建了一个 Derived 对象。这个 Derived 对象将会保存两个 tag 实例变量,一个是在 Parent 类中定义的 tag 实例变量,一个是在 Derived 类中定义的 tag 实例变量。
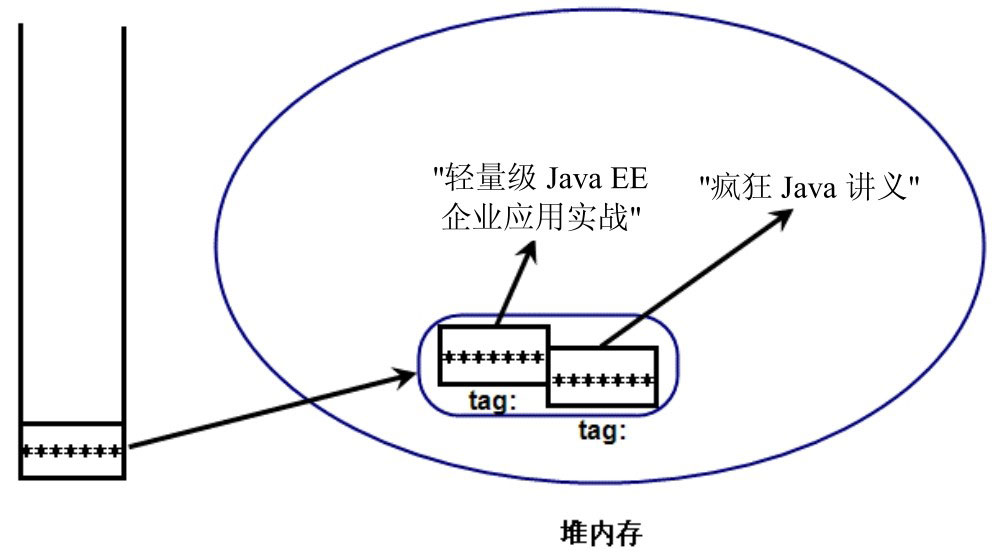
接着,程序将 Derived 对象赋给 d 变量,当在 ③ 行代码处试图通过 d 来访问 tag 实例变量时,程序将提示访问权限不允许。
这是因为访问哪个实例变量由声明该变量的类型决定,所以系统将会试图访问在 ② 行代码处定义的 tag 实例变量;程序在 ④ 行字代码处先将 d 变量强制向上转型为 Parent 类型,再通过它来访问 tag 实例变量是允许的,因为此时系统将会访问在 ① 行字代码处定义的 tag 实例变量,也就是输出“疯狂 Java 讲义”。
调用父类构造器
子类不会获得父类的构造器,但子类构造器里可以调用父类构造器的初始化代码,类似于前面所介绍的一个构造器调用另一个重载的构造器。
在一个构造器中调用另一个重载的构造器使用 this 调用来完成,在子类构造器中调用父类构造器使用 super 调用来完成。
public class Sub extends Base {
public String color;
public Sub(double size, String name, String color) {
// 通过super调用来调用父类构造器的初始化过程
super(size, name);
this.color = color;
}
public static void main(String[] args) {
// 输出Sub对象的三个Field
Sub s = new Sub(5.6, "测试对象", "红色");
System.out.println(s.size + "--" + s.name + "--" + s.color);
}
}
使用 super 调用和使用 this 调用很像,区别在于 super 调用的是其父类的构造器,而 this 调用的是同一个类中重载的构造器。
因此,使用 super 调用父类构造器也必须出现在子类构造器执行体的第一行,所以==this 调用和 super 调用不会同时出现==。
不管我们是否使用 super 调用来执行父类构造器的初始化代码,子类构造器总会调用父类构造器一次。
子类构造器调用父类构造器分如下几种情况。
- 子类构造器执行体的第一行使用
super显式调用父类构造器,系统将根据super调用里传入的实参列表调用父类对应的构造器。- 子类构造器执行体的第一行代码使用
this显式调用本类中重载的构造器,系统将根据this调用里传入的实参列表调用本类中的另一个构造器。执行本类中另一个构造器时即会调用父类构造器。- 子类构造器执行体中既没有
super调用,也没有this调用,系统将会在执行子类构造器之前,隐式调用父类无参数的构造器。
当调用子类构造器来初始化子类对象时,父类构造器总会在子类构造器之前执行;执行父类构造器时,系统会再次上溯执行其父类构造器……依此类推,创建任何 Java 对象,最先执行的总是 java.lang.Object 类的构造器。
如果创建 ClassB 的对象,系统将先执行 java.lang.Object 类的构造器,再执行 ClassA 类的构造器,然后才执行 ClassB 类的构造器,这个执行过程还是最基本的情况。
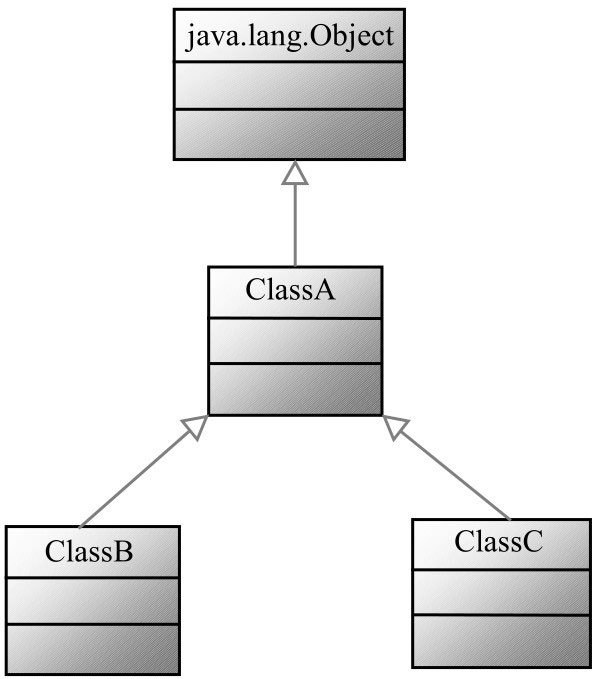
如果 ClassB 显式调用 ClassA 的构造器,而该构造器又调用了 ClassA 类中重载的构造器,则会看到 ClassA 两个构造器先后执行的情形。
class Animal extends Creature {
public Animal(String name) {
System.out.println("Animal带一个参数的构造器," + "该动物的name为" + name);
}
public Animal(String name, int age) {
// 使用this调用同一个重载的构造器
this(name);
System.out.println("Animal带两个参数的构造器," + "其age为" + age);
}
}
public class Wolf extends Animal {
public Wolf() {
// 显式调用父类有两个参数的构造器
super("灰太狼", 3);
System.out.println("Wolf无参数的构造器");
}
public static void main(String[] args) {
new Wolf();
}
}
程序的 main 方法只创建了一个 Wolf 对象,但系统在底层完成了复杂的操作。
Creature无参数的构造器
Animal带一个参数的构造器,该动物的name为灰太狼
Animal带两个参数的构造器,其age为3
Wolf无参数的构造器
创建任何对象总是从该类所在继承树最顶层类的构造器开始执行,然后依次向下执行,最后才执行本类的构造器。如果某个父类通过 this 调用了同类中重载的构造器,就会依次执行此父类的多个构造器。
提示
使用 super 会调用父类构造器但最终只会创建一个对象。super 保存的是父类型特征,而不是内存地址。
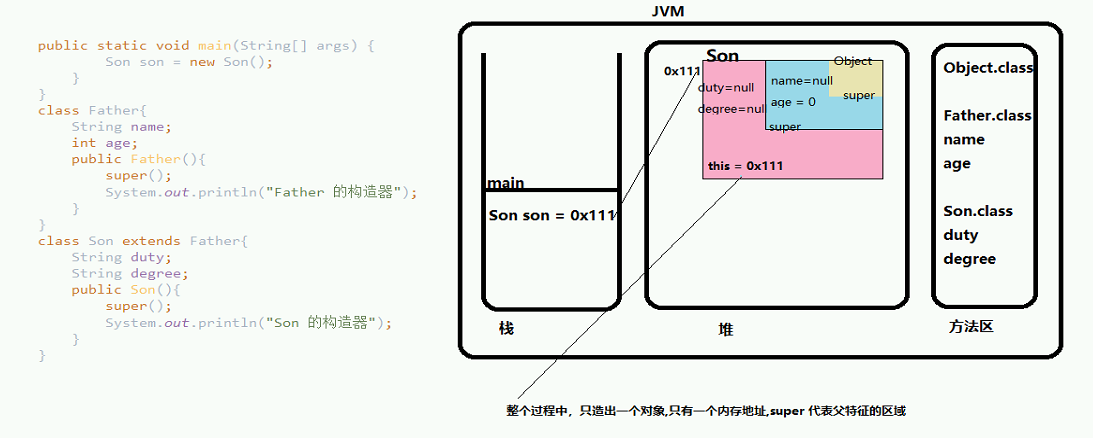
this 的实现原理:
在任何实例方法里面,都可以通过
this关键字访问到此方法所属的对象。这个访问机制对 Java 程序的编写很重要,而它的实现却非常简单,仅仅是通过Javac 编译器编译的时候把对this关键字的访问转变为对一个普通方法参数的访问,然后在虚拟机调用实例方法时自动传入此参数而已。因此在实例方法的局部变量表中至少会存在一个指向当前对象实例的局部变量,局部变量表中也会预留出第一个
Slot位来存放对象实例的引用,方法参数值从 1 开始计算。这个处理只对实例方法有效。
super 的实现原理:
super就是靠invokespecial指令来调用父类方法的。
invokespecial指令的主要作用是,用于调用一些需要特殊处理的实例方法,包括实例初始化方法、私有方法和父类方法。
继承关系中的初始化顺序
非继承关系中的初始化顺序
对于非继承关系,主类 InitialOrderWithoutExtend 中包含了静态成员变量(类变量)SampleClass 类的一个实例,普通成员变量 SampleClass 类的 2 个实例(在程序中的顺序不一样)以及一个静态代码块,其中静态代码块中如果静态成员变量 sam 不为空,则改变 sam 的引用。
public class InitialOrderWithoutExtend {
static SampleClass sam = new SampleClass("① 静态成员sam初始化");
static {
System.out.println("② static块执行");
if (sam == null) {
System.out.println("sam is null");
}
sam = new SampleClass("③ 静态块内初始化sam成员变量");
}
SampleClass sam1 = new SampleClass("⑤ 普通成员sam1初始化");
SampleClass sam2 = new SampleClass("⑥ 普通成员sam2初始化");
InitialOrderWithoutExtend() {
System.out.println("⑦ InitialOrderWithoutExtend默认构造函数被调用");
}
public static void main(String[] args) {
// 创建第1个主类对象
System.out.println("④ 第1个主类对象:");
InitialOrderWithoutExtend ts = new InitialOrderWithoutExtend();
// 创建第2个主类对象
System.out.println("⑧ 第2个主类对象:");
InitialOrderWithoutExtend ts2 = new InitialOrderWithoutExtend();
// 查看两个主类对象的静态成员:
System.out.println("⑨ 2个主类对象的静态对象:");
System.out.println("⑩ 第1个主类对象, 静态成员sam.s: " + ts.sam);
System.out.println("⑪ 第2个主类对象, 静态成员sam.s: " + ts2.sam);
}
}
class SampleClass {
// SampleClass 不能包含任何主类InitialOrderWithoutExtend的成员变量
// 否则导致循环引用,循环初始化,调用栈深度过大
// 抛出 StackOverFlow 异常
// static InitialOrderWithoutExtend iniClass1 = new InitialOrderWithoutExtend("静态成员iniClass1初始化");
// InitialOrderWithoutExtend iniClass2 = new InitialOrderWithoutExtend("普通成员成员iniClass2初始化");
String s;
SampleClass(String s) {
this.s = s;
System.out.println(s);
}
SampleClass() {
System.out.println("SampleClass默认构造函数被调用");
}
@Override public String toString() {
return this.s;
}
}
main() 方法中创建了 2 个主类对象,打印 2 个主类对象的静态成员 sam 的属性 s。
① 静态成员sam初始化
② static块执行
③ 静态块内初始化sam成员变量
④ 第1个主类对象:
⑤ 普通成员sam1初始化
⑥ 普通成员sam2初始化
⑦ InitialOrderWithoutExtend默认构造函数被调用
⑧ 第2个主类对象:
⑤ 普通成员sam1初始化
⑥ 普通成员sam2初始化
⑦ InitialOrderWithoutExtend默认构造函数被调用
⑨ 2个主类对象的静态对象:
⑩ 第1个主类对象, 静态成员sam.s: ③ 静态块内初始化sam成员变量
⑪ 第2个主类对象, 静态成员sam.s: ③ 静态块内初始化sam成员变量
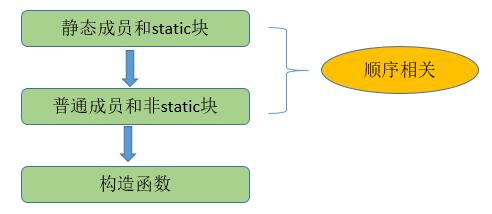
由输出结果可知,执行顺序为:
- static 静态代码块和静态成员。
- 普通成员。
- 构造函数执行。
当具有多个静态成员和静态代码块或者多个普通成员时,初始化顺序和成员在程序中申明的顺序一致。
在该程序的静态代码块中,修改了静态成员 sam 的引用。main() 方法中创建了 2 个主类对象,但是由输出结果可知,静态成员和静态代码块只进行了一次初始化,并且新建的 2 个主类对象的静态成员 sam.s 是相同的。
由此可知,类的静态成员和静态代码块在类加载中是最先进行初始化的,并且只进行一次。该类的多个实例共享静态成员,静态成员的引用指向程序最后所赋予的引用。
继承关系中的初始化顺序
此处使用了 3 个类来验证继承关系中的初始化顺序:Father 父类、Son 子类和 Sample 类。父类和子类中各自包含了非静态代码区、静态代码区、静态成员、普通成员。
public class InitialOrderWithExtend {
public static void main(String[] args) {
Father ts = new Son();
}
}
class Father {
static Sample staticSam1 = new Sample("父类 静态成员 staticSam1 初始化");
static Sample staticSam2 = new Sample("父类 静态成员 staticSam2 初始化");
static {
System.out.println("父类 static块 1 执行");
}
static {
System.out.println("父类 static块 2 执行");
}
Sample sam1 = new Sample("父类 普通成员 sam1 初始化");
Sample sam2 = new Sample("父类 普通成员 sam2 初始化");
{
System.out.println("父类 非静态块 1 执行");
}
{
System.out.println("父类 非静态块 2 执行");
}
Father() {
System.out.println("父类 默认构造函数被调用");
}
}
class Son extends Father {
static Sample staticSamSub1 = new Sample("子类 静态成员 staticSamSub1 初始化");
static Sample staticSamSub2 = new Sample("子类 静态成员 staticSamSub2 初始化");
static {
System.out.println("子类 static块1 执行");
}
static {
System.out.println("子类 static块2 执行");
}
Sample sam1 = new Sample("子类 普通成员 sam1 初始化");
Sample sam2 = new Sample("子类 普通成员 sam2 初始化");
{
System.out.println("子类 非静态块 1 执行");
}
{
System.out.println("子类 非静态块 2 执行");
}
Son() {
System.out.println("子类 默认构造函数被调用");
}
}
class Sample {
Sample(String s) {
System.out.println(s);
}
Sample() {
System.out.println("Sample默认构造函数被调用");
}
}
运行时的主类为 InitialOrderWithExtend 类,main() 方法中创建了一个子类的对象,并且使用 Father 对象指向 Son 类实例的引用(父类对象指向子类引用,多态)。
父类 static块 1 执行
父类 静态成员 staticSam1 初始化
父类 静态成员 staticSam2 初始化
父类 static块 2 执行
子类 静态成员 staticSamSub1 初始化
子类 静态成员 staticSamSub2 初始化
子类 static块1 执行
子类 static块2 执行
父类 非静态块 1 执行
父类 普通成员 sam1 初始化
父类 普通成员 sam2 初始化
父类 非静态块 2 执行
父类 默认构造函数被调用
子类 非静态块 1 执行
子类 普通成员 sam1 初始化
子类 普通成员 sam2 初始化
子类 非静态块 2 执行
子类 默认构造函数被调用
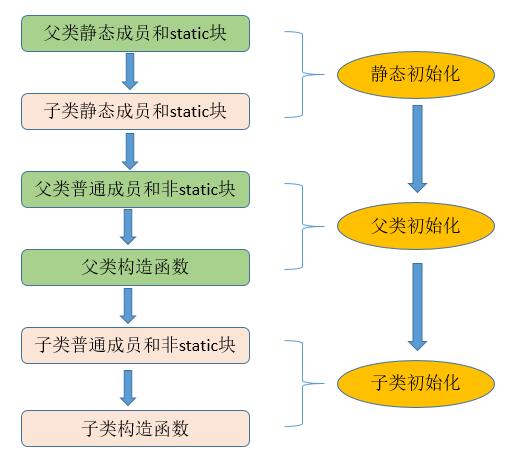
由输出结果可知,执行的顺序为:
- 父类静态代码区和父类静态成员。
- 子类静态代码区和子类静态成员。
- 父类非静态代码区和普通成员。
- 父类构造函数。
- 子类非静态代码区和普通成员。
- 子类构造函数。
与非继承关系中的初始化顺序一致的地方在于,静态代码区和父类静态成员、非静态代码区和普通成员是同一级别的,当存在多个这样的代码块或者成员时,初始化的顺序和它们在程序中申明的顺序一致;此外,静态代码区和静态成员也是仅仅初始化一次,但是在初始化过程中,可以修改静态成员的引用。
多态
Java 引用变量有两个类型:一个是编译时类型,一个是运行时类型。编译时类型由声明该变量时使用的类型决定,运行时类型由实际赋给该变量的对象决定。
如果编译时类型和运行时类型不一致,就可能出现所谓的多态Polymorphism。
多态性
class BaseClass {
public int book = 6;
public void base() {
System.out.println("父类的普通方法");
}
public void test() {
System.out.println("父类的被覆盖的方法");
}
}
public class SubClass extends BaseClass {
// 重新定义一个book实例Field隐藏父类的book实例Field
public String book = "轻量级JavaEE企业应用实战";
public void test() {
System.out.println("子类的覆盖父类的方法");
}
public void sub() {
System.out.println("子类的普通方法");
}
public static void main(String[] args) {
// 下面编译时类型和运行时类型完全一样,因此不存在多态
BaseClass bc = new BaseClass();
// 输出6
System.out.println(bc.book);
// 下面两次调用将执行BaseClass的方法
bc.base();
bc.test();
// 下面编译时类型和运行时类型完全一样,因此不存在多态
SubClass sc = new SubClass();
// 输出"轻量级J2EE企业应用实战"
System.out.println(sc.book);
// 下面调用将执行从父类继承到的base方法
sc.base();
// 下面调用将执行当前类的test方法
sc.test();
// 下面编译时类型和运行时类型不一样,多态发生
BaseClass ploymophicBc = new SubClass();
// 输出6——表明访问的是父类Field
System.out.println(ploymophicBc.book);
// 下面调用将执行从父类继承到的base方法
ploymophicBc.base();
// 下面调用将执行当前类的test方法
ploymophicBc.test();
// 因为ploymophicBc的编译时类型是BaseClass
// BaseClass类没有提供sub方法,所以下面代码编译时会出现错误
// ploymophicBc.sub();
}
}
上面程序的 main 方法中显式创建了三个引用变量,对于前两个引用变量 bc 和 sc,它们编译时类型和运行时类型完全相同,因此调用它们的 Field 和方法非常正常,完全没有任何问题。
但第三个引用变量 ploymophicBc 则比较特殊,它的编译时类型是 BaseClass,而运行时类型是 SubClass,当调用该引用变量的 test 方法(BaseClass 类中定义了该方法,子类 SubClass 覆盖了父类的该方法)时,实际执行的是 SubClass 类中覆盖后的 test 方法,这就可能出现多态了。
因为子类其实是一种特殊的父类,因此 Java 允许把一个子类对象直接赋给一个父类引用变量,无须任何类型转换,或者被称为向上转型 upcasting,向上转型由系统自动完成。
当把一个子类对象直接赋给父类引用变量,运行时调用该引用变量的方法时,其方法行为总是表现出子类方法的行为特征,而不是父类方法的行为特征,这就可能出现:相同类型的变量、调用同一个方法时呈现出多种不同的行为特征,这就是多态。
如上面的
BaseClass ploymophicBc=new SubClass();,这个ploymophicBc引用变量的编译时类型是BaseClass,而运行时类型是SubClass。
虽然 ploymophicBc 引用变量实际上确实包含 sub() 方法(例如,可以通过反射来执行该方法),但因为它的编译时类型为 BaseClass,因此编译时无法调用 sub() 方法。
对象的 Field 不具备多态性。比如上面的 ploymophicBc 引用变量,程序中输出它的 book Field 时,并不是输出 SubClass 类里定义的实例 Field,而是输出 BaseClass 类的实例 Field。
提示
通过引用变量来访问其包含的实例 Field 时,系统总是试图访问它编译时类型所定义的 Field,而不是它运行时类型所定义的 Field。
引用变量的强制类型转换
编写 Java 程序时,引用变量只能调用它编译时类型的方法,而不能调用它运行时类型的方法,即使它实际所引用的对象确实包含该方法。如果需要让这个引用变量调用它运行时类型的方法,则必须把它强制类型转换成运行时类型,强制类型转换需要借助于类型转换运算符。
类型转换运算符的用法是:(type)variable,这种用法可以将 variable 变量转换成一个 type 类型的变量。
除此之外,这个类型转换运算符还可以将一个引用类型变量转换成其子类类型。这种强制类型转换不是万能的,当进行强制类型转换时需要注意:
- 基本类型之间的转换只能在数值类型之间进行,这里所说的数值类型包括整数型、字符型和浮点型。但数值类型和布尔类型之间不能进行类型转换。
- 引用类型之间的转换只能在具有继承关系的两个类型之间进行,如果是两个没有任何继承关系的类型,则无法进行类型转换,否则编译时就会出现错误。如果试图把一个父类实例转换成子类类型,则这个对象必须实际上是子类实例才行(即编译时类型为父类类型,而运行时类型是子类类型),否则将在运行时引发
ClassCastException异常。
public class ConversionTest {
public static void main(String[] args) {
double d = 13.4;
long l = (long)d;
System.out.println(l);
int in = 5;
// 下面代码编译时出错:试图把一个数值类型变量转换为boolean类型
// 编译时会提示:不可转换的类型
// boolean b = (boolean)in;
Object obj = "Hello";
// obj变量的编译时类型为Object,是String类型的父类,可以强制类型转换
// 而且obj变量的类型实际上是String类型,所以运行时也可通过
String objStr = (String)obj;
System.out.println(objStr);
// 定义一个objPri变量,编译时类型为Object,实际类型为Integer
Object objPri = new Integer(5);
// objPri变量的编译时类型为Object,是String类型的父类
// 可以强制类型转换,而objPri变量的类型实际上是Integer类型
// 所以下面代码运行时引发ClassCastException异常
String str = (String)objPri;
}
}
在进行强制类型转换之前,先用 instanceof 运算符判断是否可以成功转换,从而避免出现 ClassCastException 异常,这样可以保证程序更加健壮。
if (objPri instanceof String) {
String str = (String)objPri;
}
intsanceof 和类型转换运算符一样,都是 Java 提供的运算符,与+、-等算术运算符的用法大致相似。
instanceof 运算符
该运算符用于操作对象实例,检查该对象是否是一个特定类型(类类型或接口类型)。
instanceof 运算符使用格式:
对象引用
instanceof对象类型
instanceof 运算符的前一个操作数通常是一个引用类型变量,后一个操作数通常是一个类(也可以是接口,可以把接口理解成一种特殊的类),它用于判断前面的对象是否是后面的类,或者其子类、实现类的实例。如果是,则返回 true,否则返回 false。
在使用 instanceof 运算符时需要注意:
instanceof运算符前面操作数的编译时类型要么与后面的类相同,要么与后面的类具有父子继承关系,否则会引起编译错误。
在任何时候对类型进行向下转型时都应该使用 instanceof 进行判断(java 规范)。
public class InstanceofTest {
public static void main(String[] args) {
// 声明hello时使用Object类,则hello的编译类型是Object
// Object是所有类的父类,但hello变量的实际类型是String
Object hello = "Hello";
// String是Object类的子类,可以进行instanceof运算。返回true
System.out.println("字符串是否是Object类的实例:" + (hello instanceof Object));
// 返回true
System.out.println("字符串是否是String类的实例:" + (hello instanceof String));
// Math是Object类的子类,可以进行instanceof运算。返回false
System.out.println("字符串是否是Math类的实例:" + (hello instanceof Math));
// String实现了Comparable接口,所以返回true
System.out.println("字符串是否是Comparable接口的实例:" + (hello instanceof Comparable));
String a = "Hello";
// String类既不是Math类,也不是Math类的父类
// 所以下面代码编译无法通过
// System.out.println("字符串是否是Math类的实例:" + (a instanceof Math));
}
}
继承与组合
继承是实现类重用的重要手段,但继承带来了一个最大的坏处:破坏封装。
相比之下,组合也是实现类重用的重要方式,而采用组合方式来实现类重用则能提供更好的封装性。
使用继承的注意点
封装:
每个类都应该封装它内部信息和实现细节,而只暴露必要的方法给其他类使用。但在继承关系中,子类可以直接访问父类的 Field(内部信息)和方法,从而造成子类和父类的严重耦合。
继承:
父类的实现细节对子类不再透明,子类可以访问父类的 Field 和方法,并可以改变父类方法的实现细节(例如,通过方法重写的方式来改变父类的方法实现),从而导致子类可以恶意篡改父类的方法。
为了保证父类有良好的封装性,不会被子类随意改变,设计父类通常应该遵循如下规则。
- 尽量隐藏父类的内部数据。尽量把父类的所有 Field 都设置成
private访问类型,不要让子类直接访问父类的 Field。- 不要让子类可以随意访问、修改父类的方法。
- 父类中那些仅为辅助其他的工具方法,应该使用
private访问控制符修饰,让子类无法访问该方法;- 如果父类中的方法需要被外部类调用,则必须以
public修饰,但又不希望子类重写该方法,可以使用final修饰符来修饰该方法;- 如果希望父类的某个方法被子类重写,但不希望被其他类自由访问,则可以使用
protected来修饰该方法。- 尽量不要在父类构造器中调用将要被子类重写的方法。
class Base {
public Base() {
test();
}
public void test() {
// ①号test方法
System.out.println("将被子类重写的方法");
}
}
public class Sub extends Base {
private String name;
public void test() {
// ②号test方法
System.out.println("子类重写父类的方法," + "其name字符串长度" + name.length());
}
public static void main(String[] args) {
// 下面代码会引发空指针异常
Sub s = new Sub();
}
}
当系统试图创建 Sub 对象时,同样会先执行其父类构造器,当创建 Sub 对象时,会先执行 Base 类中的 Base 构造器,而 Base 构造器中调用了 test 方法——并不是调用 ① 号 test 方法,而是调用 ② 号 test 方法,此时 Sub 对象的 name Field 是 null,因此将引发空指针异常。
相关信息
如果想把某些类设置成最终类,即不能被当成父类,则可以使用 final 修饰这个类,例如 JDK 提供的 java.lang.String 类和 java.lang.System 类。
除此之外,使用 private 修饰这个类的所有构造器,从而保证子类无法调用该类的构造器,也就无法继承该类。对于把所有的构造器都使用 private 修饰的父类而言,可另外提供一个静态方法,用于创建该类的实例。
到底何时需要从父类派生新的子类呢?不仅需要保证子类是一种特殊的父类,而且需要具备以下两个条件之一。
- 子类需要额外增加属性,而不仅仅是属性值的改变。例如从
Person类派生出Student子类,Person类里没有提供grade(年级)属性,而Student类需要grade属性来保存Student对象就读的年级,这种父类到子类的派生,就符合 Java 继承的前提。- 子类需要增加自己独有的行为方式(包括增加新的方法或重写父类的方法)。例如从
Person类派生出Teacher类,其中Teacher类需要增加一个teaching方法,该方法用于描述Teacher对象独有的行为方式:教学。
利用组合实现复用
如果需要复用一个类,除了把这个类当成基类来继承之外,还可以把该类当成另一个类的组合成分,从而允许新类直接复用该类的 public 方法。不管是继承还是组合,都允许在新类(对于继承就是子类)中直接复用旧类的方法。
组合是把旧类对象作为新类的 Field 嵌入,用以实现新类的功能,用户看到的是新类的方法,而不能看到被嵌入对象的方法。因此,通常需要在新类里使用 private 修饰被嵌入的旧类对象。
class Animal {
private void beat() {
System.out.println("心脏跳动...");
}
public void breath() {
beat();
System.out.println("吸一口气,吐一口气,呼吸中...");
}
}
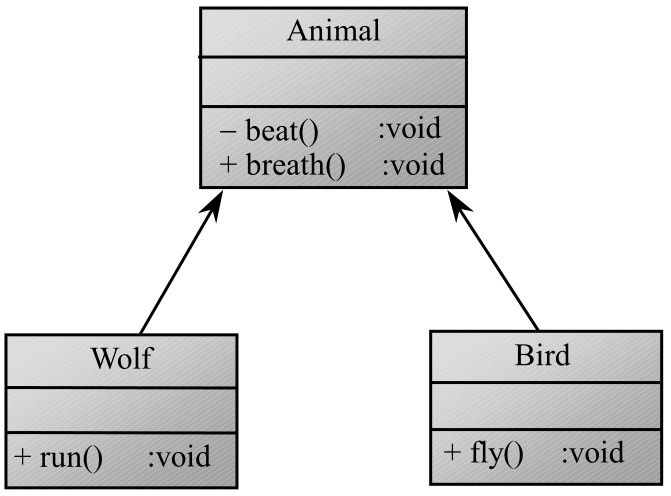
// 继承Animal,直接复用父类的breath方法
class Bird extends Animal {
public void fly() {
System.out.println("我在天空自在的飞翔...");
}
}
// 继承Animal,直接复用父类的breath方法
class Wolf extends Animal {
public void run() {
System.out.println("我在陆地上的快速奔跑...");
}
}
public class InheritTest {
public static void main(String[] args) {
Bird b = new Bird();
b.breath();
b.fly();
Wolf w = new Wolf();
w.breath();
w.run();
}
}
如果仅仅从软件复用的角度来看,将上面三个类的定义改为如下形式也可实现相同的复用。
class Animal {
private void beat() {
System.out.println("心脏跳动...");
}
public void breath() {
beat();
System.out.println("吸一口气,吐一口气,呼吸中...");
}
}
class Bird {
// 将原来的父类嵌入原来的子类,作为子类的一个组合成分
private Animal a;
public Bird(Animal a) {
this.a = a;
}
// 重新定义一个自己的breath方法
public void breath() {
// 直接复用Animal提供的breath方法来实现Bird的breath方法
a.breath();
}
public void fly() {
System.out.println("我在天空自在的飞翔...");
}
}
class Wolf {
// 将原来的父类嵌入原来的子类,作为子类的一个组合成分
private Animal a;
public Wolf(Animal a) {
this.a = a;
}
// 重新定义一个自己的breath方法
public void breath() {
// 直接复用Animal提供的breath方法来实现Wolf的breath方法
a.breath();
}
public void run() {
System.out.println("我在陆地上的快速奔跑...");
}
}
public class CompositeTest {
public static void main(String[] args) {
// 此时需要显式创建被嵌入的对象
Animal a1 = new Animal();
Bird b = new Bird(a1);
b.breath();
b.fly();
// 此时需要显式创建被嵌入的对象
Animal a2 = new Animal();
Wolf w = new Wolf(a2);
w.breath();
w.run();
}
}
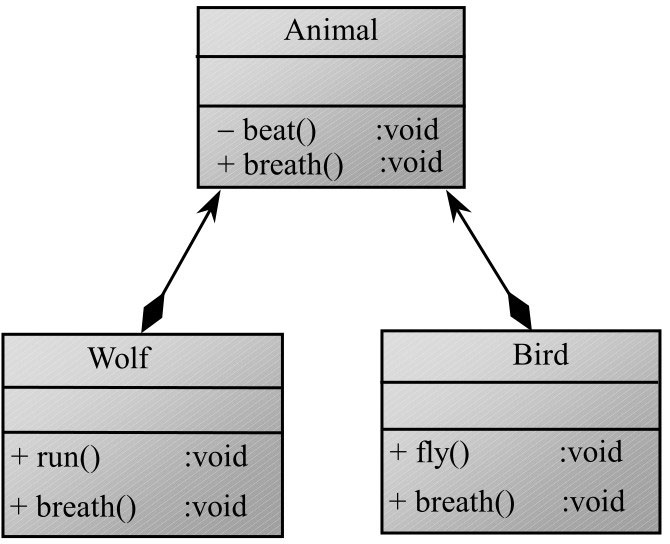
此时的 Wolf 对象和 Bird 对象由 Animal 对象组合而成,因此在上面程序中创建 Wolf 对象和 Bird 对象之前先创建 Animal 对象,并利用这个 Animal 对象来创建 Wolf 对象和 Bird 对象。
相关信息
使用组合关系来实现复用时,需要创建两个 Animal 对象,是不是意味着使用组合关系时系统开销更大?
不会。当创建一个子类对象时,系统不仅需要为该子类定义的 Field 分配内存空间,而且需要为它的父类所定义的 Field 分配内存空间。
如果采用继承的设计方式,假设父类定义了 2 个 Field,子类定义了 3 个 Field,当创建子类实例时,系统需要为子类实例分配 5 块内存空间;如果采用组合的设计方式,先创建被嵌入类实例,此时需要分配 2 块内存空间,再创建整体类实例,也需要分配 3 块内存空间,只是需要多一个引用变量来引用被嵌入的对象。
通过这个分析来看,继承设计与组合设计的系统开销不会有本质的差别。
到底该用继承?还是该用组合呢?继承是对已有的类做一番改造,以此获得一个特殊的版本。简而言之,就是将一个较为抽象的类改造成能适用于某些特定需求的类。
因此,对于上面的 Wolf 和 Animal 的关系,使用继承更能表达其现实意义。
用一个动物来合成一匹狼毫无意义:狼并不是由动物组成的。反之,如果两个类之间有明确的整体、部分的关系,例如
Person类需要复用Arm类的方法(Person对象由Arm对象组合而成),此时就应该采用组合关系来实现复用,把Arm作为Person类的嵌入 Field,借助于Arm的方法来实现Person的方法,这是一个不错的选择。
总之,继承要表达的是一种“是(is-a)”的关系,而组合表达的是“有(has-a)”的关系
初始化块
Java 使用构造器来对单个对象进行初始化操作,使用构造器先完成整个 Java 对象的状态初始化,然后将 Java 对象返回给程序,从而让该 Java 对象的信息更加完整。与构造器作用非常类似的是初始化块,它也可以对 Java 对象进行初始化操作。
使用初始化块
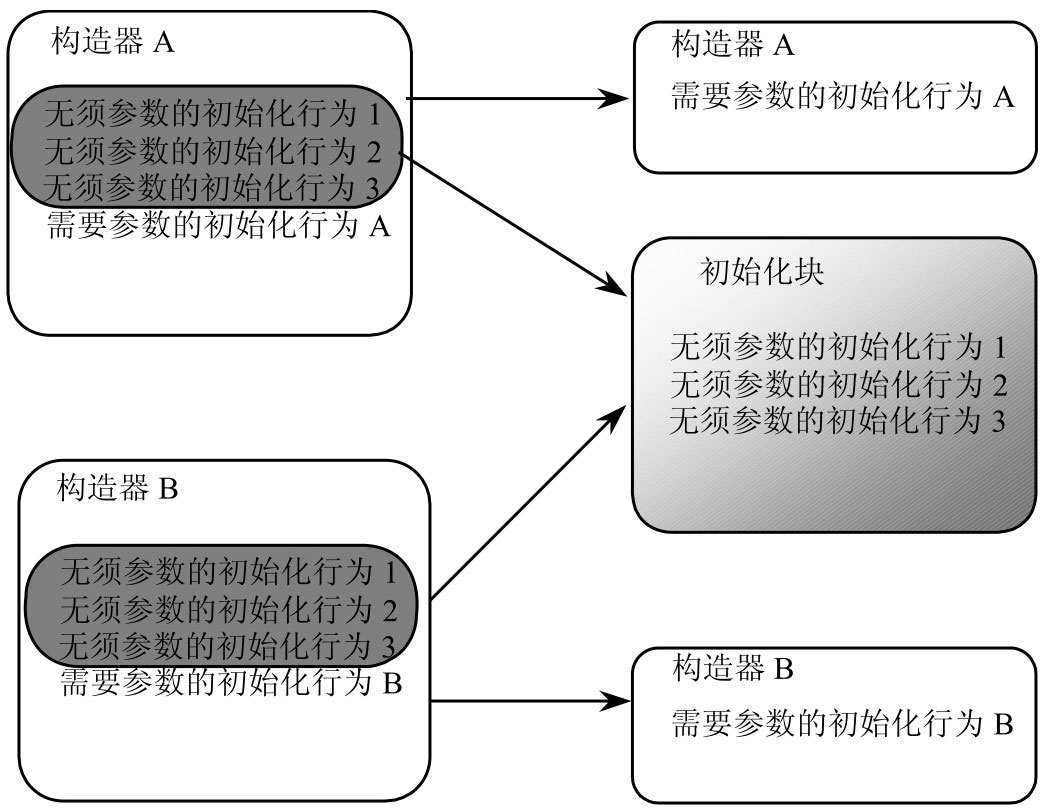
初始化块是 Java 类里可出现的第 4 种成员(前面依次有 Field、方法和构造器),一个类里可以有多个初始化块,相同类型的初始化块之间有顺序:前面定义的初始化块先执行,后面定义的初始化块后执行。
[修饰符] {
//始化块的可执行性代码
…
}
初始化块的修饰符只能是 static,使用 static 修饰的初始化块被称为静态初始化块。初始化块里的代码可以包含任何可执行性语句,包括定义局部变量、调用其他对象的方法,以及使用分支、循环语句等。
public class Person {
// 下面定义一个初始化块
{
int a = 6;
// 在初始化块中
if (a > 4) {
System.out.println("Person初始化块:局部变量a的值大于4");
System.out.println("Person的初始化块");
}
// 定义第二个初始化块{
System.out.println("Person的第二个初始化块");
}
// 定义无参数的构造器
public Person() {
System.out.println("Person类的无参数构造器");
}
public static void main(String[] args) {
new Person();
}
}
Person初始化块:局部变量a的值大于4
Person的初始化块
Person的第二个初始化块
Person类的无参数构器
当创建 Java 对象时,系统总是先调用该类里定义的初始化块,如果一个类里定义了 2 个普通初始化块,则前面定义的初始化块先执行,后面定义的初始化块后执行。
初始化块虽然也是 Java 类的一种成员,但它没有名字,也就没有标识,因此无法通过类、对象来调用初始化块。初始化块只在创建 Java 对象时隐式执行,而且在执行构造器之前执行。
提示
虽然 Java 允许一个类里定义 2 个普通初始化块,但这没有任何意义。因为初始化块是在创建 Java 对象时隐式执行的,而且它们总是全部执行,因此我们完全可以把多个普通初始化块合并成一个初始化块,从而可以让程序更加简洁,可读性更强。
初始化块和构造器的作用非常相似,它们都用于对 Java 对象执行指定的初始化操作,但它们之间依然存在一些差异,下面具体分析初始化块和构造器之间的差异。
普通初始化块、声明实例 Field 指定的默认值都可认为是对象的初始化代码,它们的执行顺序与源程序中的排列顺序相同。
public class InstancelnitTest {
// 先执行初始化块将a Field赋值为6
{
a = 6;
}
// 再执行将a Field赋值为9
int a = 9;
public static void main(String[] args) {
// 下面代码将输出9
System.out.println(new InstancelnitTest().a);
}
}
提示
当 Java 创建一个对象时,系统先为该对象的所有实例 Field 分配内存(前提是该类已经被加载过了),接着程序开始对这些实例变量执行初始化,其初始化顺序是:先执行初始化块或声明 Field 时指定的初始值,再执行构造器里指定的初始值。
初始化块和构造器
从某种程度上来看,初始化块是构造器的补充,初始化块总是在构造器执行之前执行。系统同样可使用初始化块来进行对象的初始化操作。
与构造器不同的是,初始化块是一段固定执行的代码,它不能接收任何参数。因此初始化块对同一个类的所有对象所进行的初始化处理完全相同。
如果有一段初始化处理代码对所有对象完全相同,且无须接收任何参数,就可以把这段初始化处理代码提取到初始化块中。
如果两个构造器中有相同的初始化代码,这些初始化代码无须接收参数,就可以把它们放在初始化块中定义。通过把多个构造器中的相同代码提取到初始化块中定义,能更好地提高初始化代码的复用,提高整个应用的可维护性。
与构造器类似,创建一个 Java 对象时,不仅会执行该类的普通初始化块和构造器,而且系统会一直上溯到 java.lang.Object 类,先执行 java.lang.Object 类的初始化块,开始执行 java.lang.Object 的构造器,依次向下执行其父类的初始化块,开始执行其父类的构造器……最后才执行该类的初始化块和构造器。
如果希望类加载后对整个类进行某些初始化操作,例如当 Person 类加载后,则需要把 Person 类的 eyeNumber 类 Field 初始化为 2,此时需要使用 static 关键字来修饰初始化块,使用 static 修饰的初始化块被称为静态初始化块。
静态初始化块
如果定义初始化块时使用了 static 修饰符,则这个初始化块就变成了静态初始化块,也被称为类初始化块。静态初始化块是类相关的,系统将在类初始化阶段执行静态初始化块,而不是在创建对象时才执行。因此静态初始化块总是比普通初始化块先执行。
静态初始化块通常用于对类 Field 执行初始化处理。静态初始化块不能对实例 Field 进行初始化处理。
与普通初始化块类似的是,系统在类初始化阶段执行静态初始化块时,不仅会执行本类的静态初始化块,而且还会一直上溯到 java.lang.Object 类(如果它包含静态初始化块),先执行 java.lang.Object 类的静态初始化块(如果有),然后执行其父类的静态初始化块……最后才执行该类的静态初始化块,经过这个过程,才完成了该类的初始化过程。
只有当类初始化完成后,才可以在系统中使用这个类,包括访问这个类的类方法、类 Field,或者用这个类来创建实例。
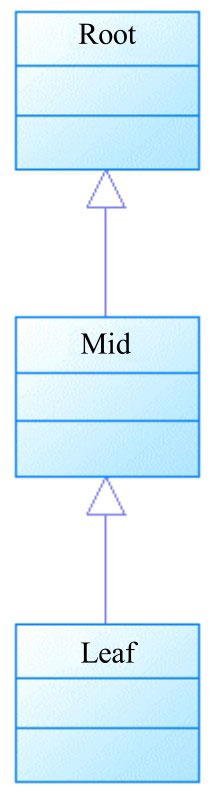
class Root {
static {
System.out.println("Root的静态初始化块");
}
{
System.out.println("Root的普通初始化块");
}
public Root() {
System.out.println("Root的无参数的构造器");
}
}
class Mid extends Root {
static {
System.out.println("Mid的静态初始化块");
}
{
System.out.println("Mid的普通初始化块");
}
public Mid() {
System.out.println("Mid的无参数的构造器");
}
public Mid(String msg) {
// 通过this调用同一类中重载的构造器
this();
System.out.println("Mid的带参数构造器,其参数值:" + msg);
}
}
class Leaf extends Mid {
static {
System.out.println("Leaf的静态初始化块");
}
{
System.out.println("Leaf的普通初始化块");
}
public Leaf() {
// 通过super调用父类中有一个字符串参数的构造器
super("疯狂Java讲义");
System.out.println("执行Leaf的构造器");
}
}
public class Test {
public static void main(String[] args) {
new Leaf();
new Leaf();
}
}
上面定义了三个类,其继承树如图。
在上面主程序中两次执行 new Leaf(); 代码,创建两个 Leaf 对象,输出结果如下。
Root的静态初始化块
Mid的静态初始化块
Leaf的静态初始化块
Root的普通初始化块
Root的无参数的构造器
Mid的普通初始化块
Mid的无参数的构造器
Mid的带参数构造器,其参数值:疯狂Java讲义
Leaf的普通初始化块
执行Leaf的构造器
Root的普通初始化块
Root的无参数的构造器
Mid的普通初始化块
Mid的无参数的构造器
Mid的带参数构造器,其参数值:疯狂Java讲义
Leaf的普通初始化块
执行Leaf的构造器
其中
Root的静态初始化块
Mid的静态初始化块
Leaf的静态初始化块
类初始化阶段,先执行最顶层父类的静态初始化块,然后依次向下,直到执行当前类的静态初始化块。
Root的无参数的构造器
Mid的普通初始化块
Mid的无参数的构造器
Mid的带参数构造器,其参数值:疯狂Java讲义
Leaf的普通初始化块
执行Leaf的构造器
对象初始化阶段,先执行最顶层父类的初始化块、最顶层父类的构造器,然后依次向下,直到执行当前类的初始化块、当前类的构造器。
一旦 Leaf 类初始化成功后,Leaf 类在该虚拟机里将一直存在,因此当第二次创建 Leaf 实例时无须再次对 Leaf 类进行初始化。
静态初始化块和声明静态 Field 时所指定的初始值都是该类的初始化代码,它们的执行顺序与源程序中的排列顺序相同。
public class StaticInitTest {
// 先执行静态初始化块将a静态Field赋值为6
static {
a = 6;
}
// 再执行将a静态Field赋值为9
static int a = 9;
public static void main(String[] args) {
// 下面代码将输出9
System.out.println(StaticInitTest.a);
}
}
上面程序中定义了两次对 a 静态 Field 进行赋值,执行结果是 a 值为 9,这表明 static int a = 9 这行静态初始化块后执行。